A Guide to the Zenera Architecture
The work should be done by agents, and the platform should make those agents trustworthy. This is how that works, from a single agent to whole systems of agents that mirror your enterprise.
Most enterprise software still assumes a human will sit in front of it - clicking through screens, wiring up integrations, babysitting jobs, and fixing things when they break. Zenera starts from a different assumption: the work should be done by agents, and the platform should make those agents trustworthy.
This guide builds up from the ground: first the big picture, then a single agent, then the runtime that agents run on, and finally whole systems of agents that mirror your business and keep themselves working.
"Agents write plain code. An agent writes ordinary Python that opens files, reads data, and writes results - exactly as if it were on a laptop with a local disk. Everything hard and dangerous about doing that for real - versioning, transactions, permissions, running across a cluster, recovering from crashes - is handled underneath by the platform."
Platform Overview
A single map of how the whole platform fits together, before we zoom in.
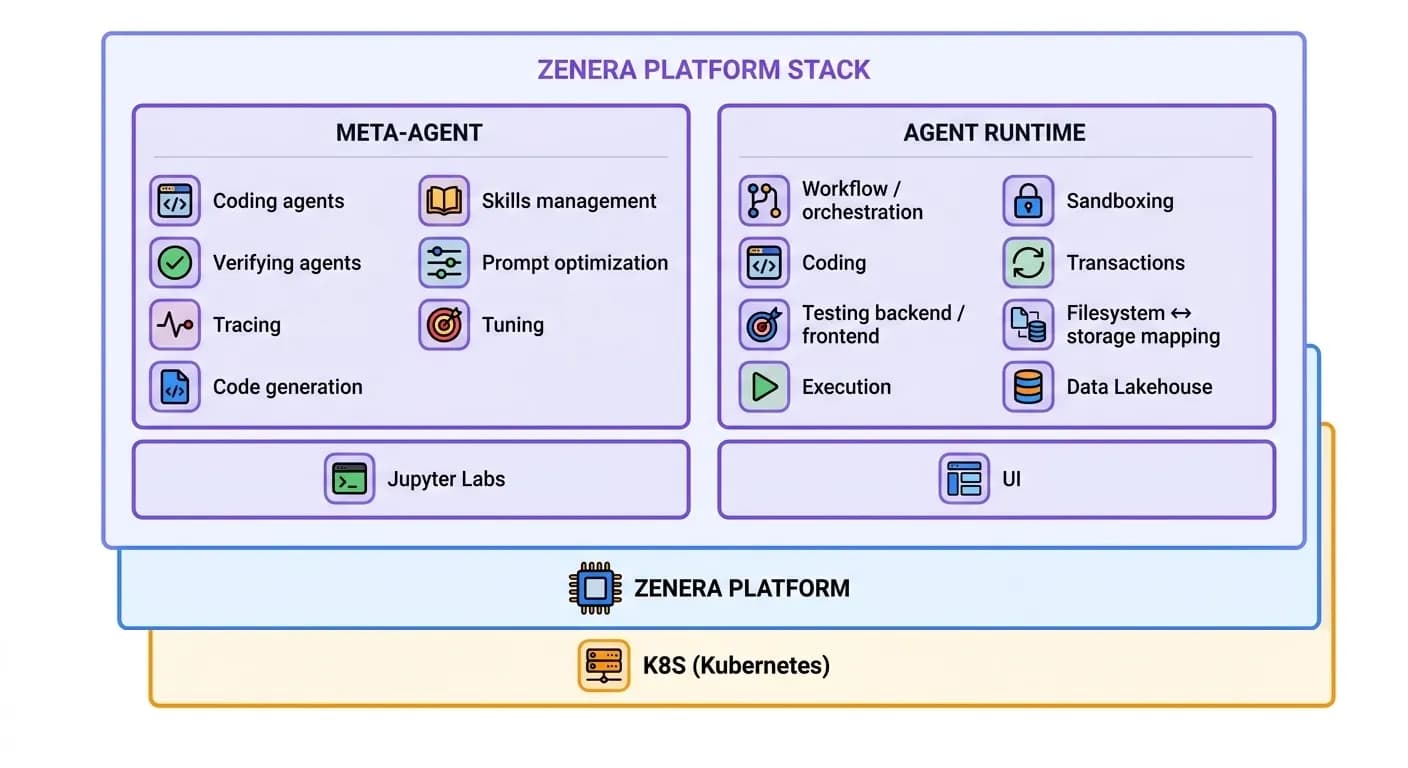
- The left column is the Meta-Agent side: coding agents, verifiers, tracing, code generation, skills management, prompt optimization, and tuning, plus a separate Jupyter Labs workspace aligned with the UI layer.
- The right column is the runtime side: workflow/orchestration, coding, testing backend/frontend, execution, sandboxing, transactions, filesystem-to-storage mapping, Data Lakehouse, and UI.
- The diagram treats Zenera Platform as the shared substrate for both sides, running on top of Kubernetes.
Anatomy & Autonomy of an Agent
What a typical Zenera agent is made of, how it runs, and how the same core loop adapts to one-shot jobs, long-running services, and UI generation.
What an Agent Is Made Of
A typical agent has three parts.
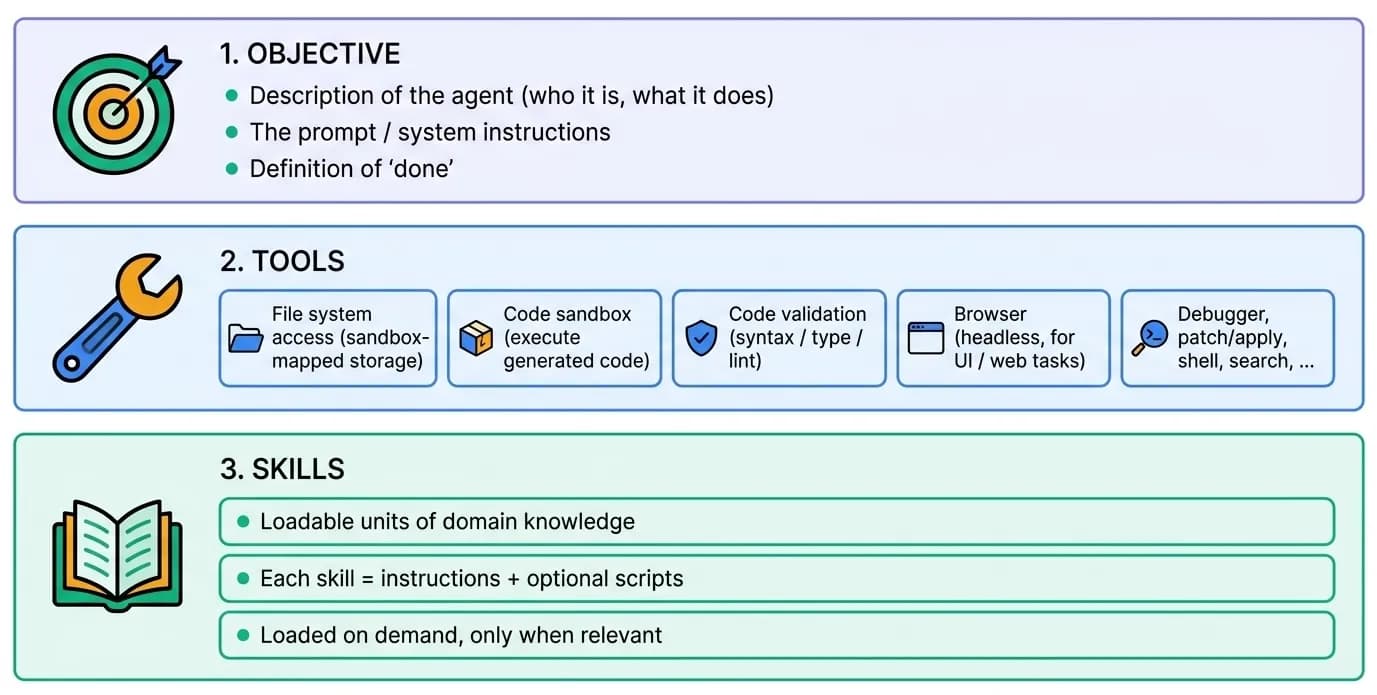
- Objective - the agent's identity and goal: a description of its role, the prompt / system instructions that shape its behavior, and a success condition for knowing the objective is achieved.
- Tools - the actions it invokes: file system access, a code sandbox, code validation, a headless browser, and utilities (debugger, patch/apply, shell, search).
- Skills - loadable units of domain knowledge. The agent loads a skill only when the current state calls for it, keeping its working context focused.
The Core Loop
At its heart, an agent runs in a loop until its objective is achieved: analyze state, load skills if necessary, generate code (plain Python against the sandbox file system), validate code with static checks, execute in the sandbox, analyze the output, use tools to debug and patch, and loop.
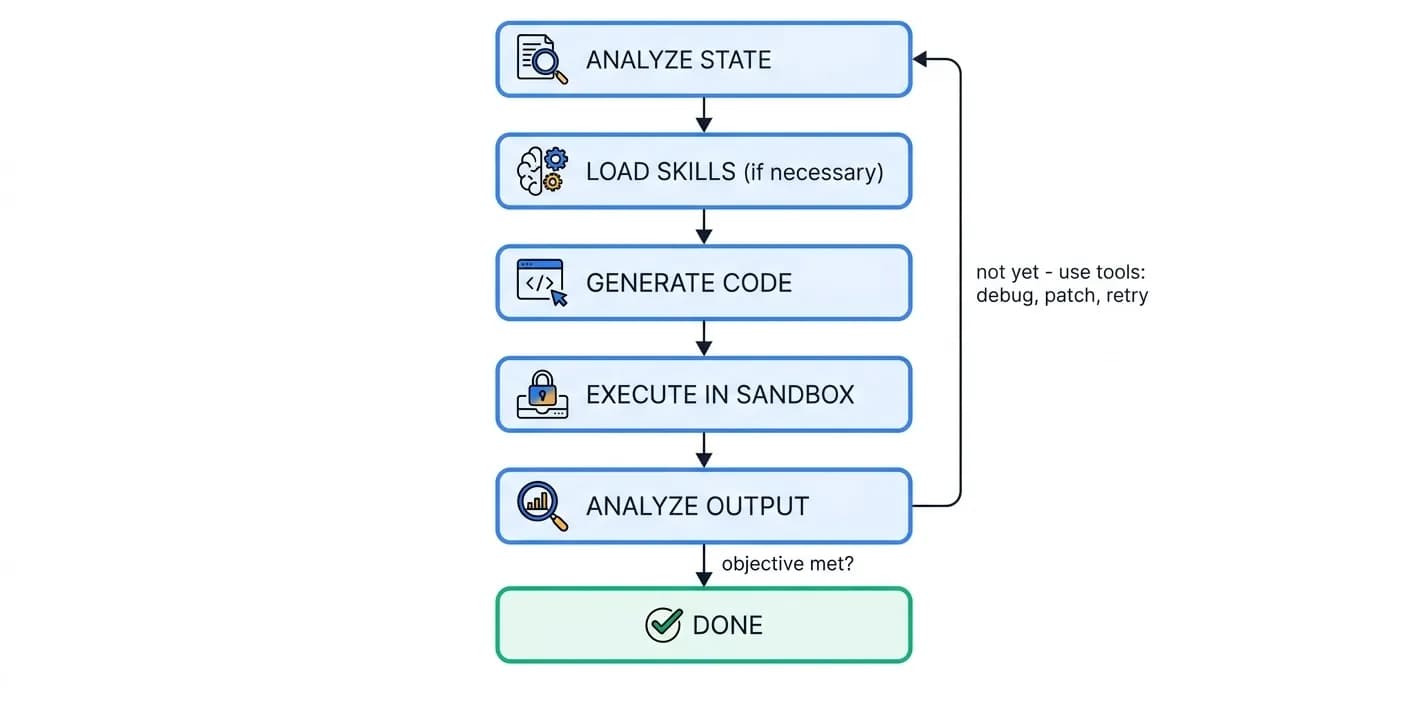
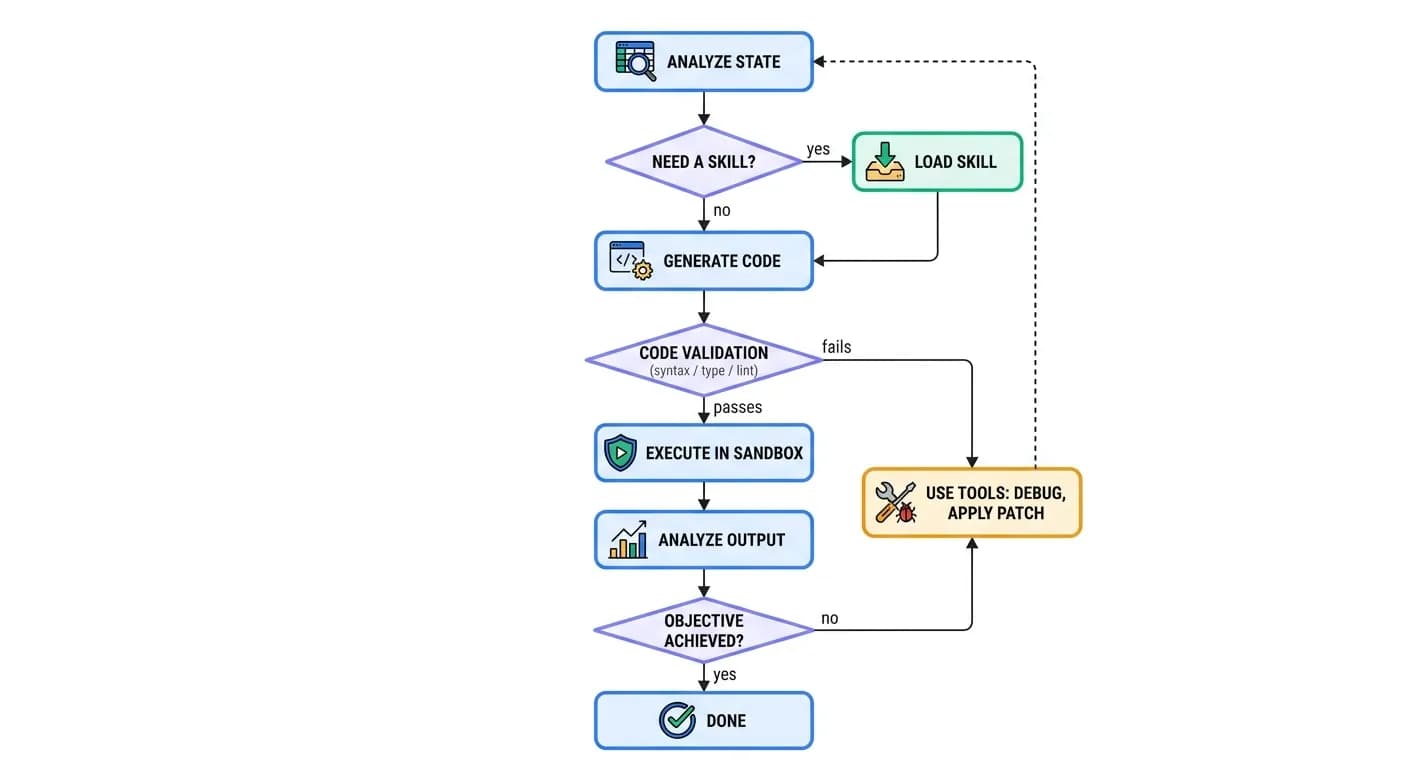
"The generated code is just regular Python using the standard file system. The sandbox maps the file system to storage and hides all the transaction and storage complexity, so the agent never writes a line of storage-specific code."
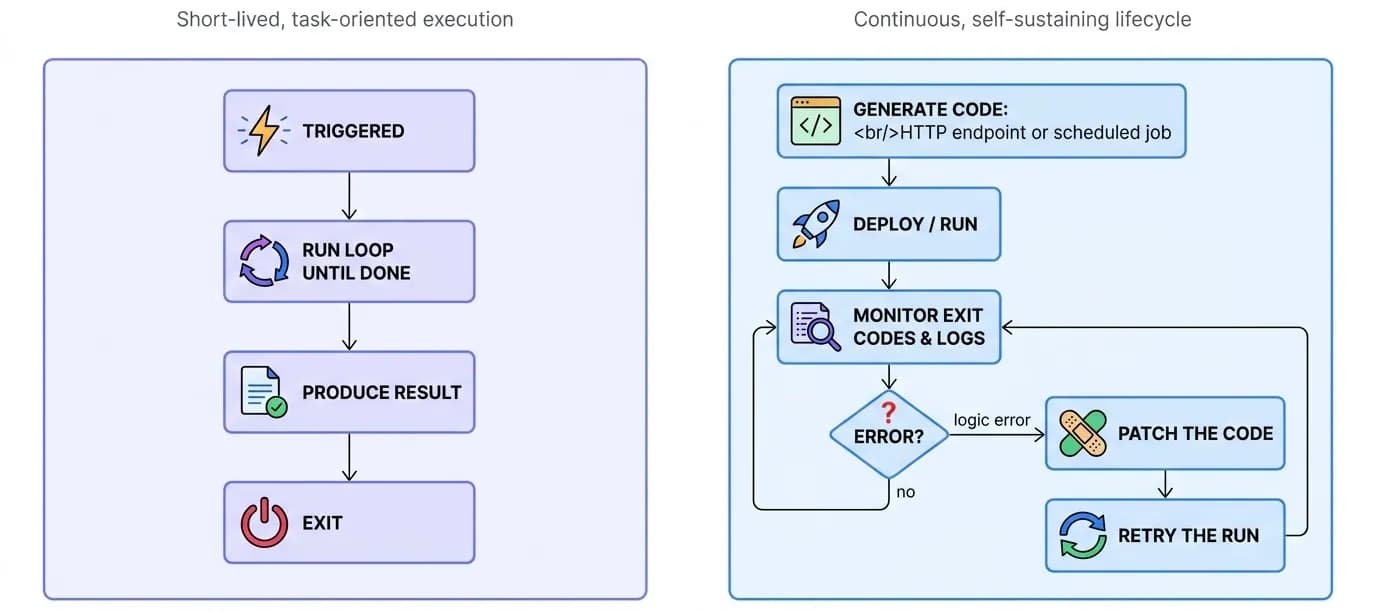
One-Shot vs. Long-Running Agents
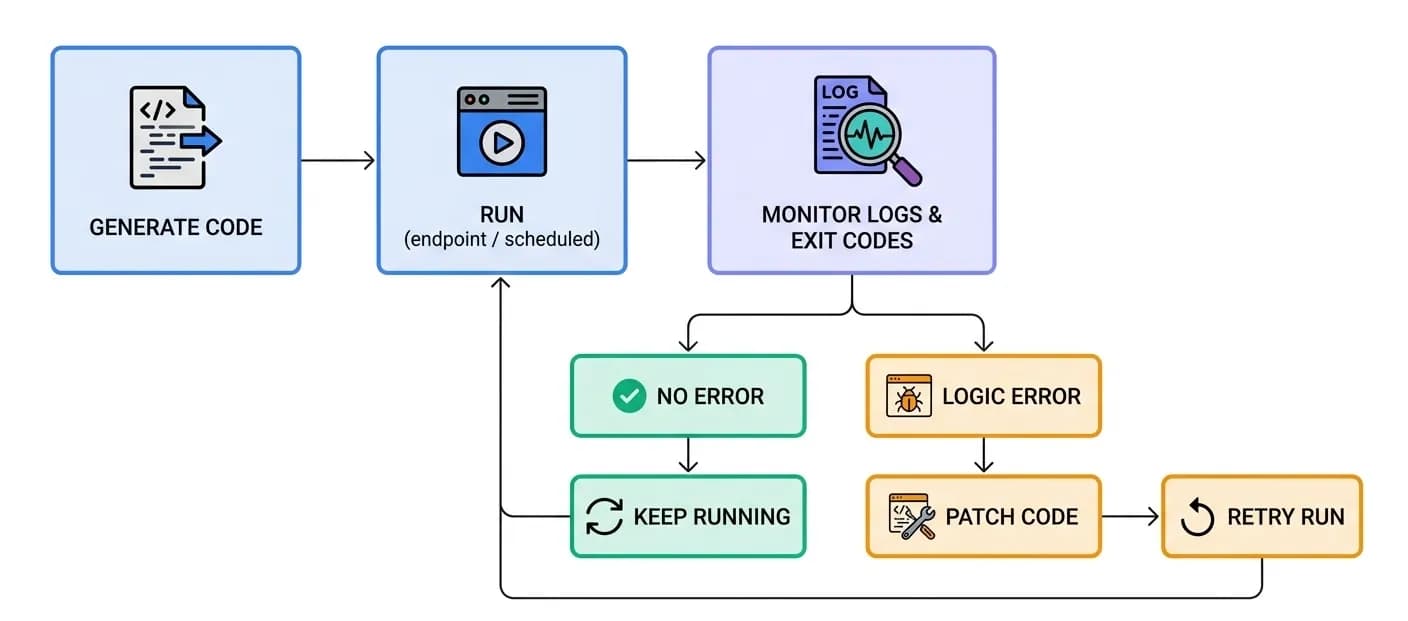
The same loop produces two very different lifecycles. A one-shot agent runs the loop, produces a result, and exits. A long-running agent generates code that keeps running - an HTTP endpoint or a scheduled job - then shifts into a supervisory role: it monitors exit codes and logs, and when it detects a logic error it patches the code and retries, self-healing without a human in the loop.
UI Generation Agents
A UI generation agent runs a similar loop, geared toward validating an interface rather than a data result: generate UI code, open it in an isolated headless browser, simulate a user, track errors from logs and from the screen via DOM snapshots and screenshots at different resolutions, classify issues by severity, generate and apply a patch, and loop until the UI is validated.
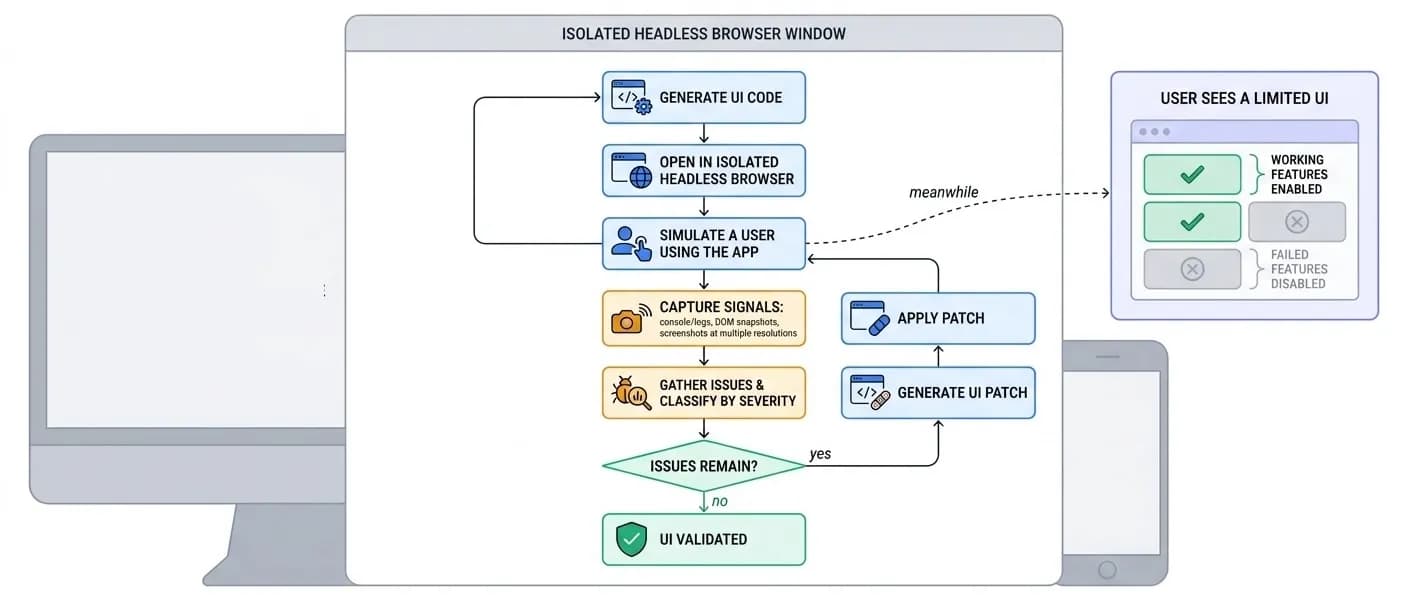
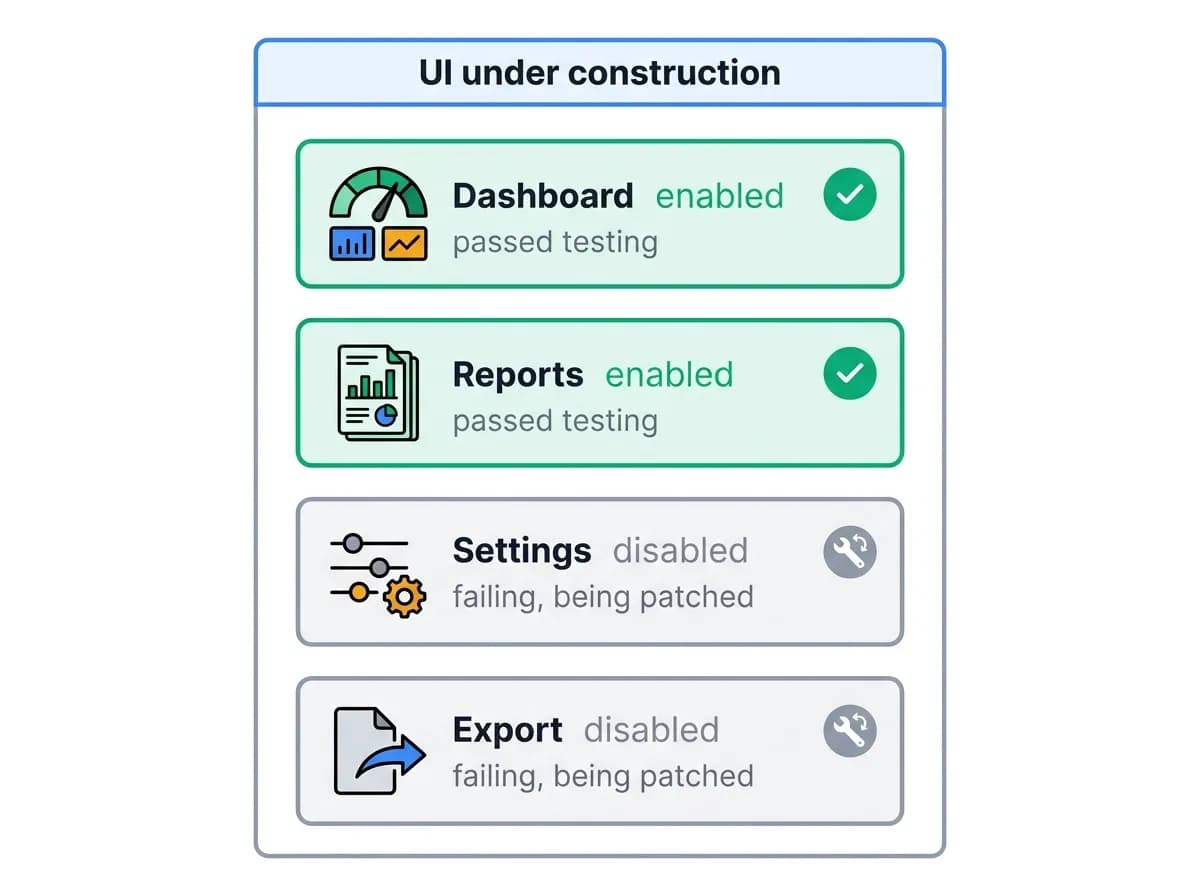
Progressive availability: while the validation loop runs, the user already sees a limited version of the UI - features that worked during testing are enabled, while features that failed are disabled. As the loop fixes issues, more of the interface becomes available.
Summary
| Aspect | One-Shot | Long-Running | UI Generation |
|---|---|---|---|
| Ends? | Runs and exits | Keeps running | Runs until UI validated |
| Output | A result / artifact | A live endpoint or scheduled job | A working UI |
| Validation | Output analysis | Logs + exit codes | Browser sim, DOM, screenshots |
| Self-healing | Retry within loop | Patch on logic error, retry | Patch UI, re-test |
| Code target | Standard FS in sandbox | Standard FS in sandbox | UI code + standard FS |
Across all three, the agent is the same animal: an objective, a set of tools, and loadable skills, driven by a generate → execute → analyze → patch loop. In every case the code it writes is ordinary code on an ordinary file system - the sandbox quietly turns that into transactional, versioned, crash-safe storage operations.
Agent Runtime
The layer that takes the plain code an agent generates and runs it safely, at scale, on enterprise data of any size - hiding RBAC, LakeFS branches and transactions, storage mapping, Kubernetes scheduling, and crash recovery.
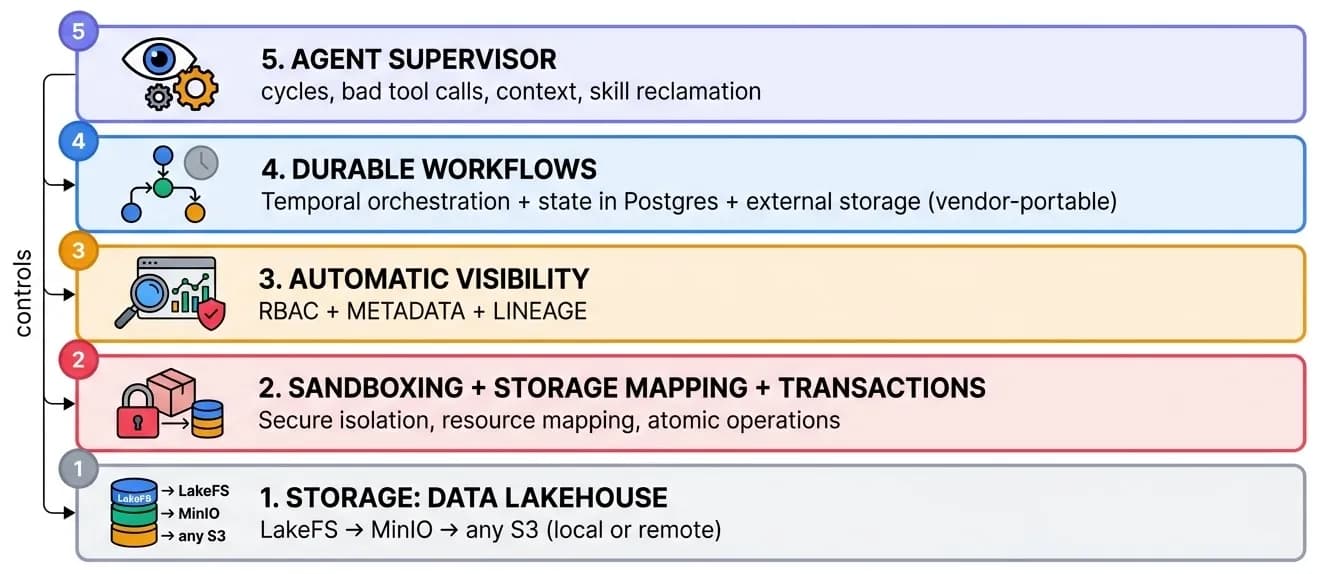
For a deeper look at how a single execution runs in under 200ms - warm worker pools, lazy data mounting, and crash-safe commits - see the Transactional Execution Runtime.
Storage: A Local Data Lakehouse
The storage layer is a complete Data Lakehouse that runs entirely on local infrastructure - no cloud dependency required. Any S3 backend sits at the bottom, MinIO provides an S3-compatible interface, and LakeFS adds git-like semantics - branches, commits, merges, rollbacks - over the data itself.
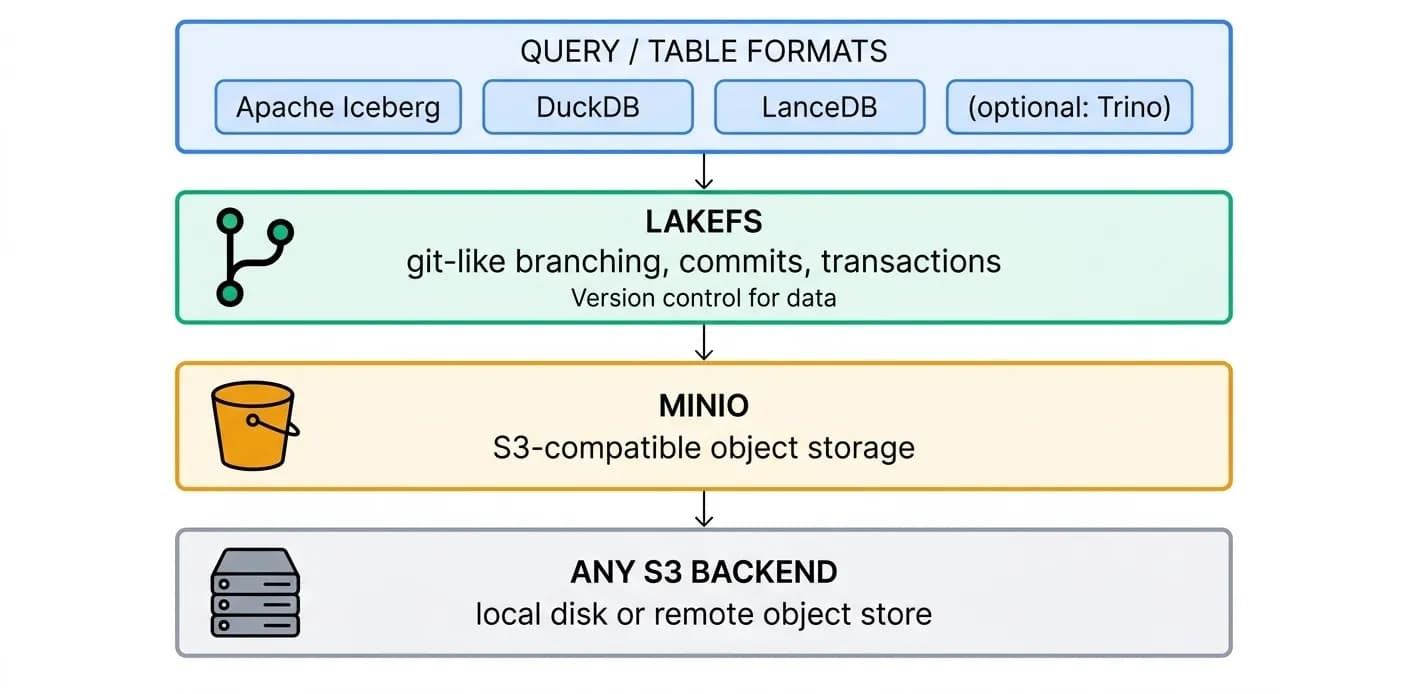
- Transactions for unreliable agents - agents fail (OOM, bad API response, buggy code, eviction). LakeFS makes every execution a transaction: work happens on an isolated branch, a successful run commits it atomically, a failed run is rolled back. Storage is always left consistent.
- Heterogeneous data, lakehouse-native - Apache Iceberg for large evolving tables, DuckDB for fast in-process SQL, LanceDB for vector and multimodal data, and optional Trino as a distributed query engine. All formats resolve to objects in the same LakeFS-versioned store.
Sandboxing, Storage Mapping, and Transactions
The sandbox is the bridge between “agent writes plain code” and “that code runs transactionally on a distributed lakehouse.” It does three jobs at once: compute allocation (CPU/memory/GPU, possibly on a different host, with Kubernetes scheduling), storage mapping (LakeFS URLs appear as local filesystem paths, streamed on demand), and transactions (every write lands on the run's isolated branch, committed on success and rolled back on failure).
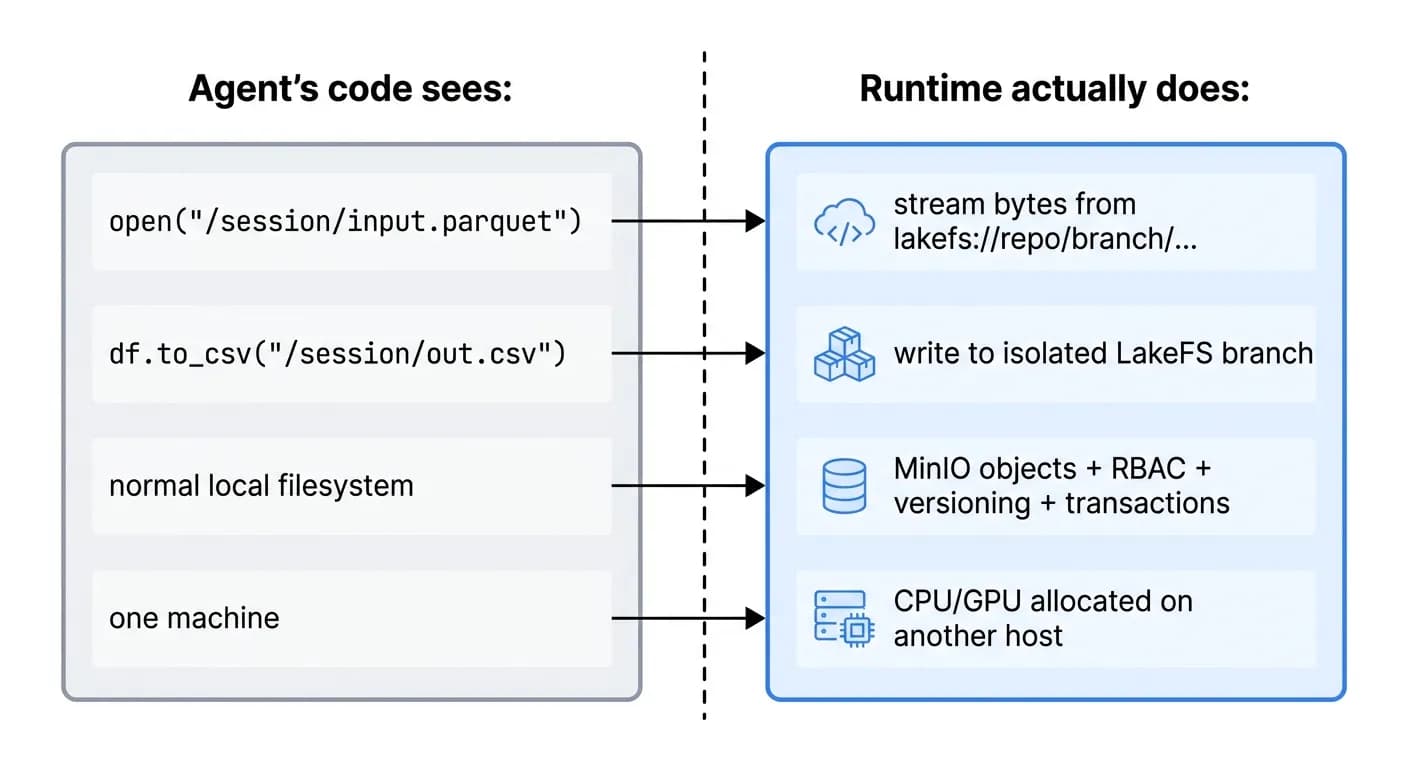
"The agent's Python code just sees a regular local filesystem. The complexity of LakeFS branching, repository permissions, transactions, and distributed compute is completely hidden by the sandbox runtime."
Automatic Visibility: RBAC, Metadata, and Lineage
Output files produced by agents are not opaque blobs - the storage architecture maintains the context around them automatically.
- Metadata - every generated file carries schema, column types, row counts, summaries, and provenance, so another agent can immediately understand its contents.
- Data lineage - every transaction records what code ran, on what inputs, and what outputs it produced, so the runtime can trace all data flows end to end.
- RBAC - access control is enforced by the runtime at the storage layer, not coded by the agent. Each agent inherits the permissions of its context automatically.
Durable Agent Workflows
A single sandboxed execution is one step. A real agent is a long-lived process that loops - analyze, generate, execute, inspect, patch, retry - for seconds or for weeks. The runtime guarantees an agent runs beginning to end, across crashes, restarts, outages, and even infrastructure migrations, by running every agent as a durable workflow on Temporal.
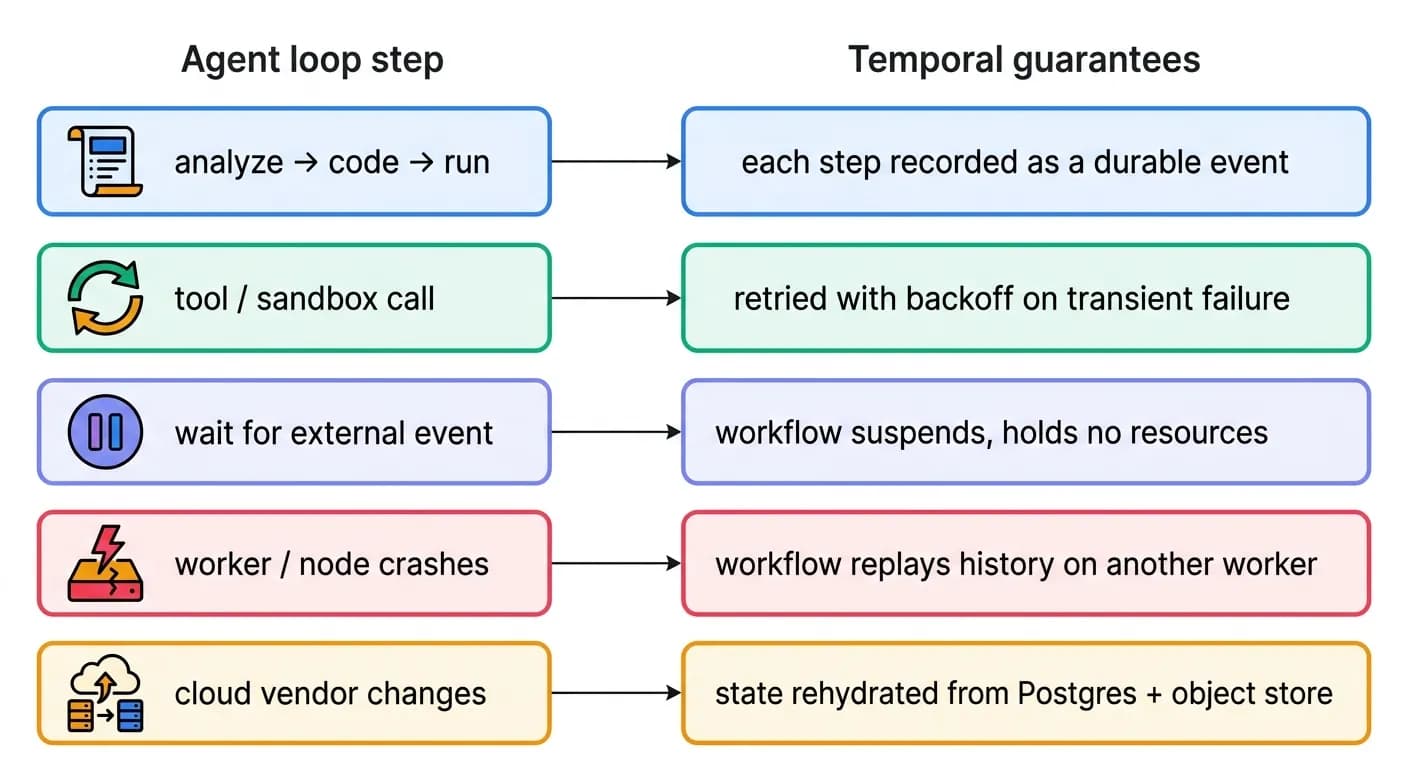
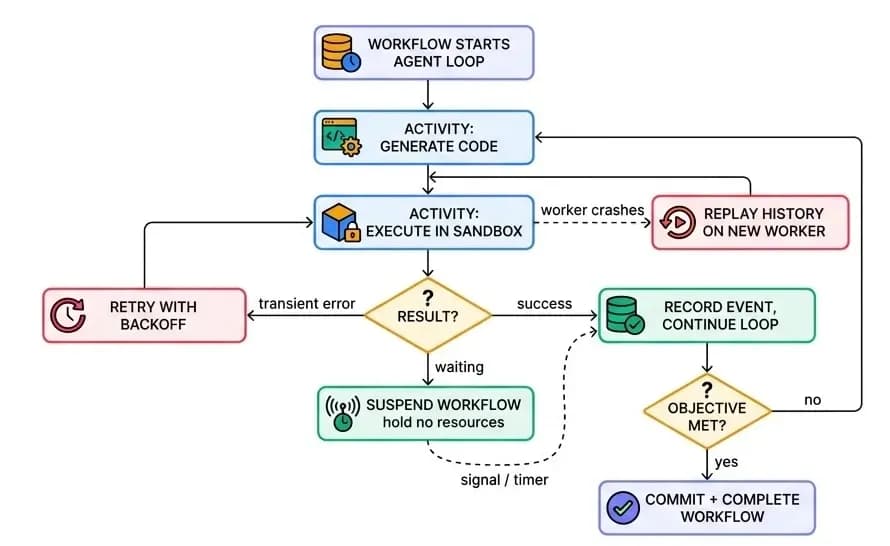
Temporal records every step as a durable event in an append-only history. If a worker pod crashes mid-loop, Temporal replays the history on a fresh worker and resumes exactly where the agent left off. State lives in PostgreSQL (workflow state) and external object storage (data state) - not in the process - so an agent is fully portable and can rehydrate on any worker, in any cluster, even after a move to a different cloud vendor.
Temporal, PostgreSQL, and the observability stack all ship pre-wired in the Enterprise Deployment Helm chart - no glue code required.
"An agent process can die at any moment and lose nothing. The process is just a temporary executor of a workflow whose real state lives in the database and the object store."
This matters most for long-running integration agents that mirror an ERP, a CRM, or a raw SQL database and run for days, weeks, or indefinitely:
| Reality of long-running agents | What durable workflows provide |
|---|---|
| The source API has a multi-hour outage | Workflow suspends and resumes automatically when the source returns; no lost progress |
| A worker pod is rescheduled or upgraded | History replays on a new worker; the sync continues from the last committed point |
| Token / credential expiry mid-sync | The failing activity retries after refresh without restarting the whole job |
| The schema drifts and code must be regenerated | The patch-and-retry step is just another recorded activity in the loop |
| The platform migrates to a new cloud | State rehydrates from Postgres + object storage; the agent keeps running |
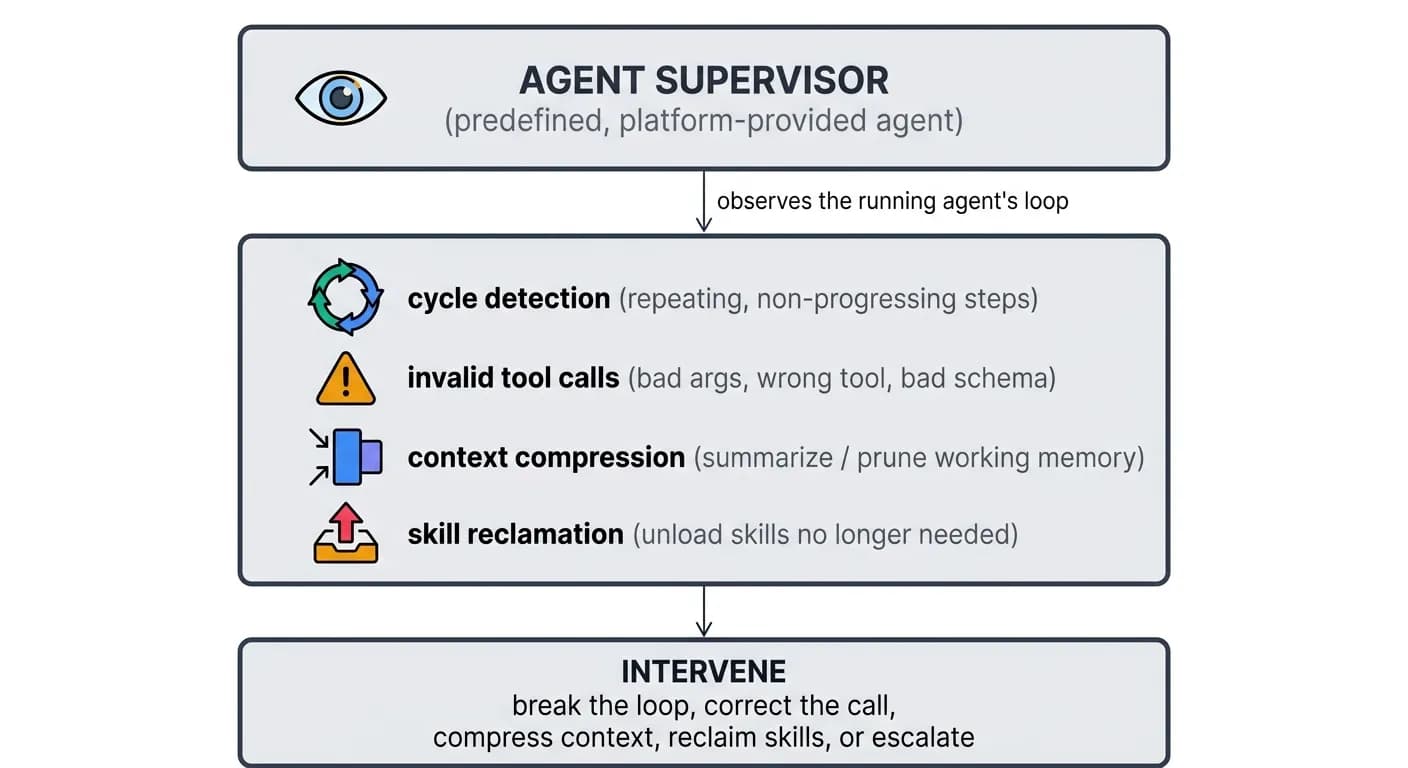
The Agent Supervisor
Durable workflows guarantee an agent runs reliably to completion - but not that it makes healthy progress. Every agent therefore runs under the watch of the Agent Supervisor, a platform-provided agent whose only job is to observe other agents'trajectories and keep them healthy: cycle detection, catching invalid tool calls, context compression, and skill reclamation. The structured execution records the supervisor and Meta-Agent reason over are explored in Trajectories and Observability.
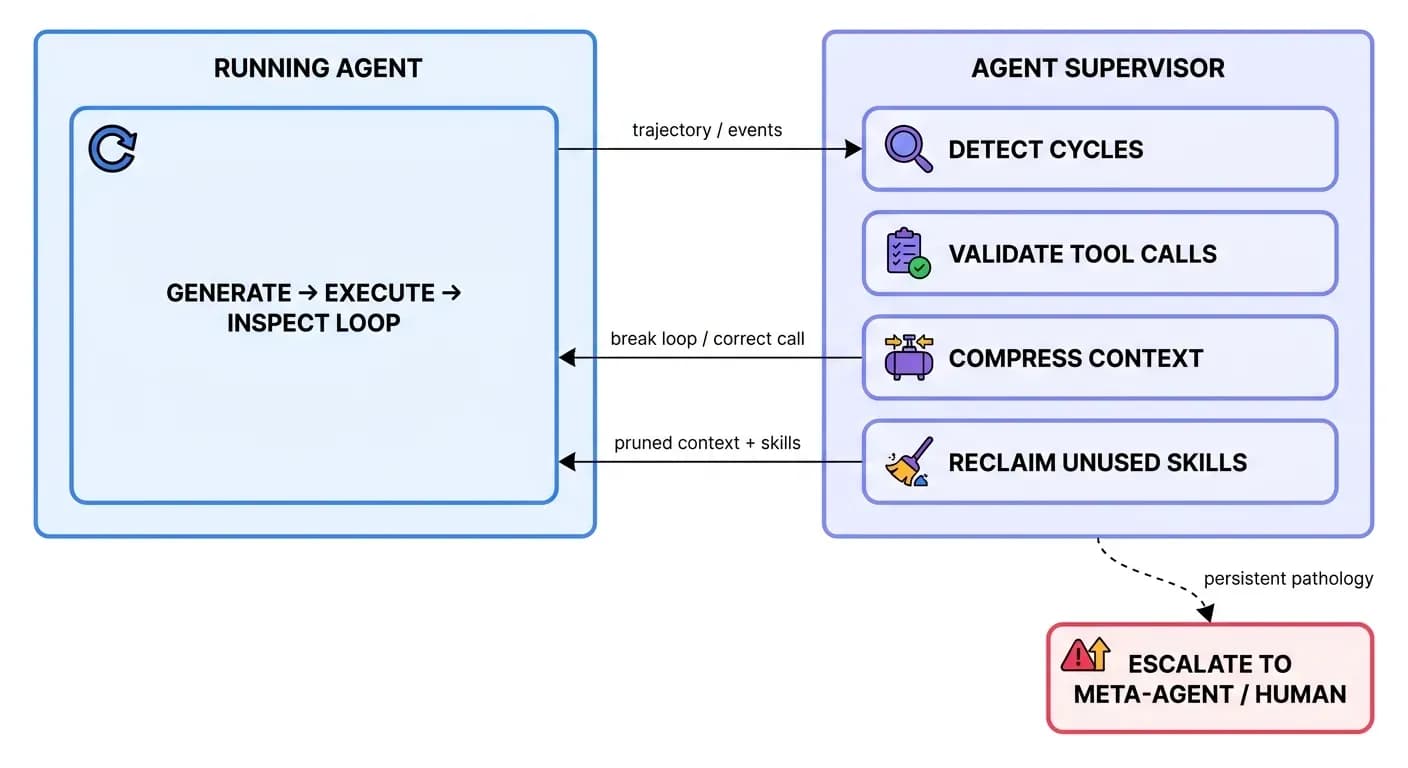
A Failure That Heals Itself
The clearest illustration is the case the runtime is built for: an agent loads a several-hundred-gigabyte file into a pandas DataFrame, has already written some output, and then gets killed by an OOM event. Because all partial writes went to an isolated branch that was rolled back, the data is never corrupted. If the error persists, the runtime escalates back to the agent, which can patch the code (e.g. switch to chunked or streaming processing) - all as a durable workflow under the eye of the Agent Supervisor.
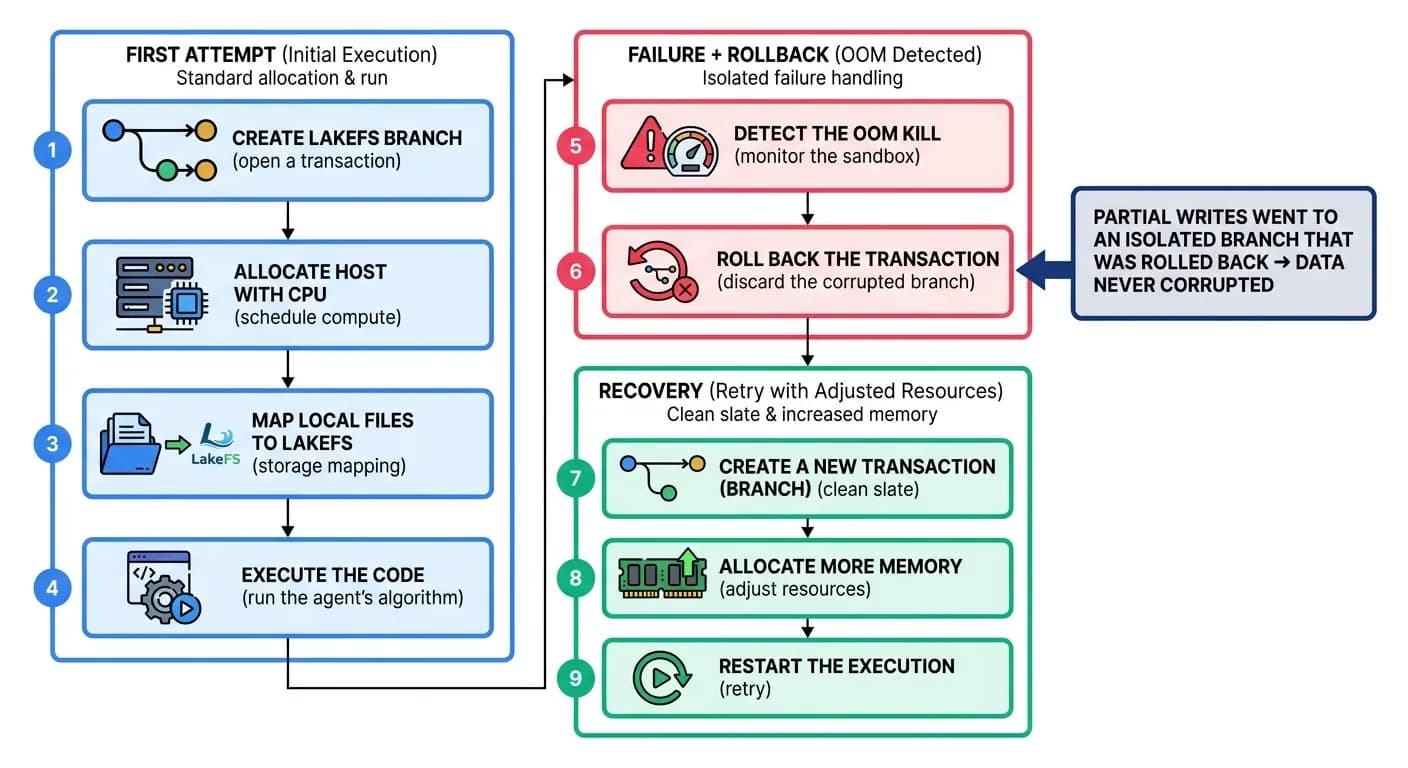
"The runtime guarantees a consistent final state of the storage. Agents write code as if it were a local host with a local filesystem - the runtime manages all the complexity of security/RBAC, LakeFS, transactions, and Kubernetes load balancing underneath."
Agentic Systems
How agents connect to the messy reality of enterprise systems - ERPs, CRMs, raw SQL databases, the open internet, internal services - and compose into a living, self-maintaining data and application stack.
The Big Picture
A Zenera agentic system is a layered pipeline of agents that turns external systems of record into clean data, clean data into insight, and insight into interactive applications - coordinated through events, governed by RBAC, and driven from a single chat interface. The connective tissue between every layer is the transactional file system and the event bus: a commit emits an event, and the next layer wakes on that event.
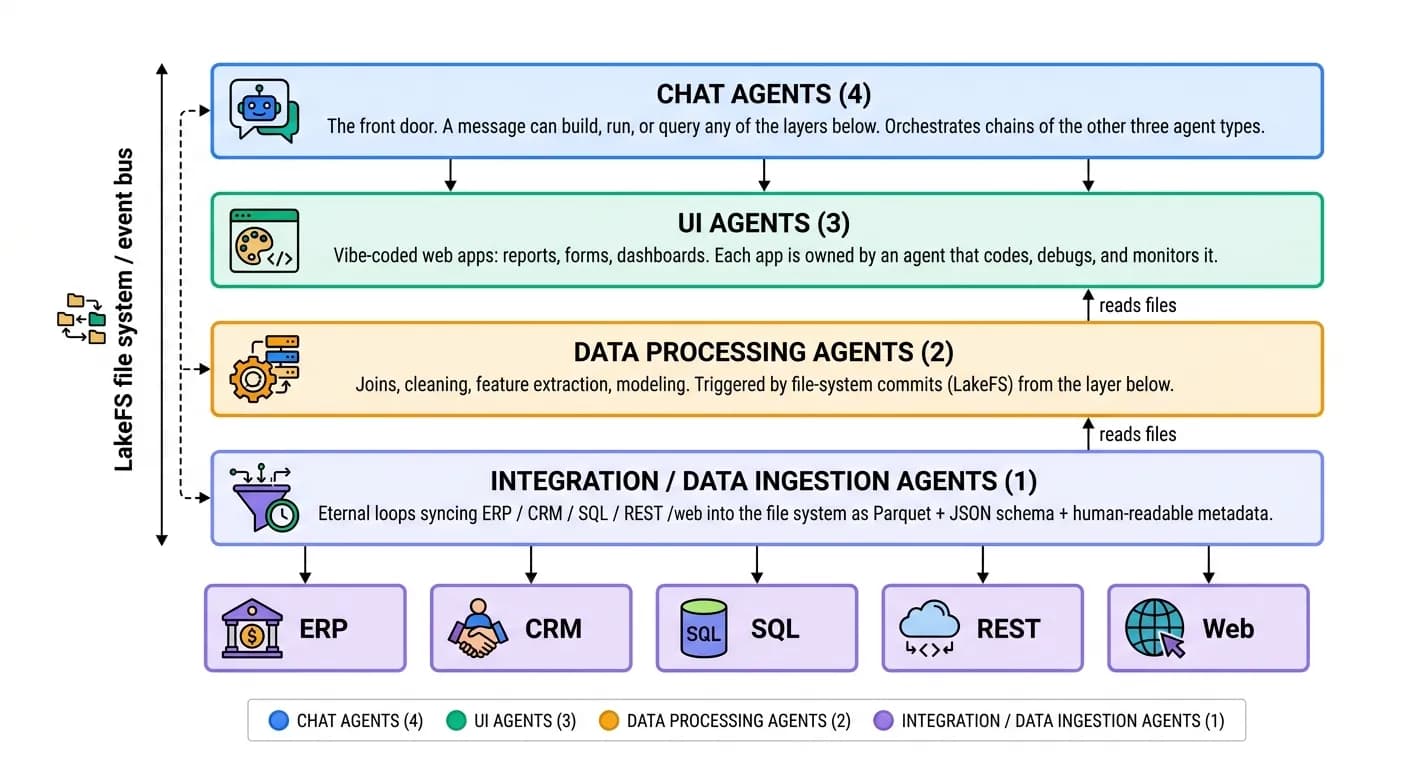
Integration / Data Ingestion Agents
Job: keep a faithful, query-ready mirror of external systems inside the platform's file system - continuously, safely, and adaptively. They run in an eternal loop calling external APIs, databases, REST endpoints, or the open web, monitor their own execution for schema drift, rate limits, and outages, and operate strictly inside their granted RBAC scope. They are triggered by a timer or an explicit REST API call.
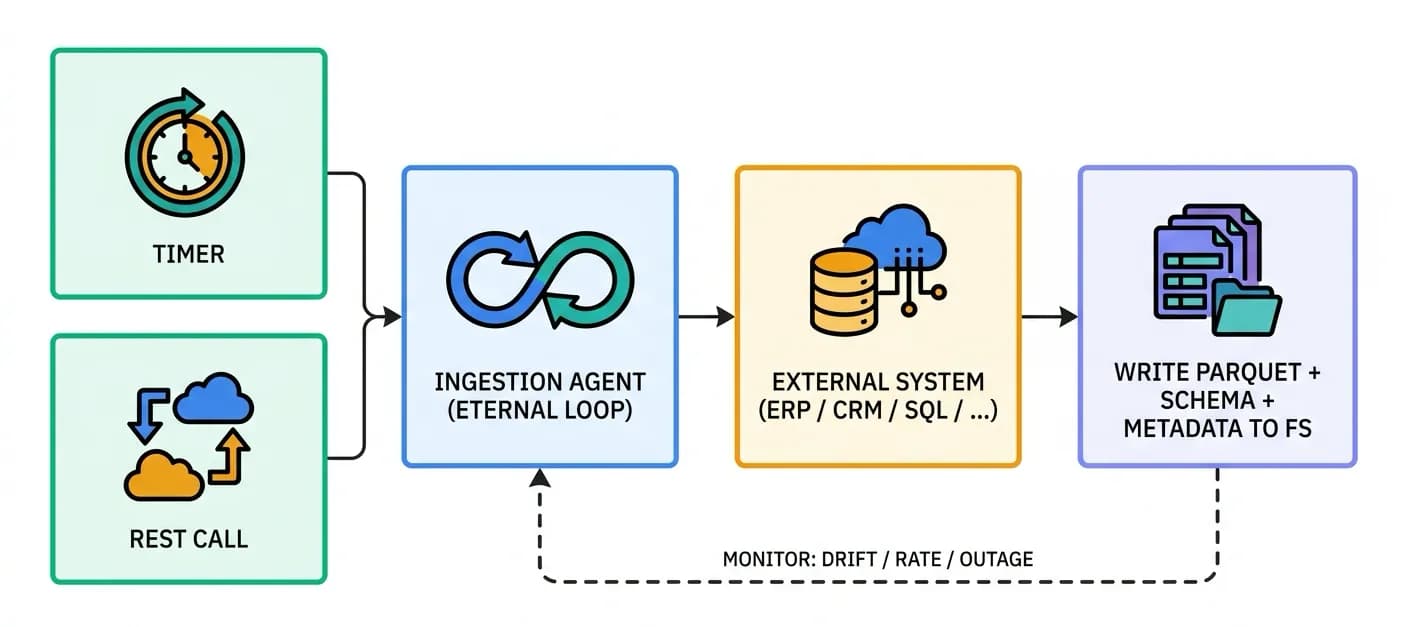
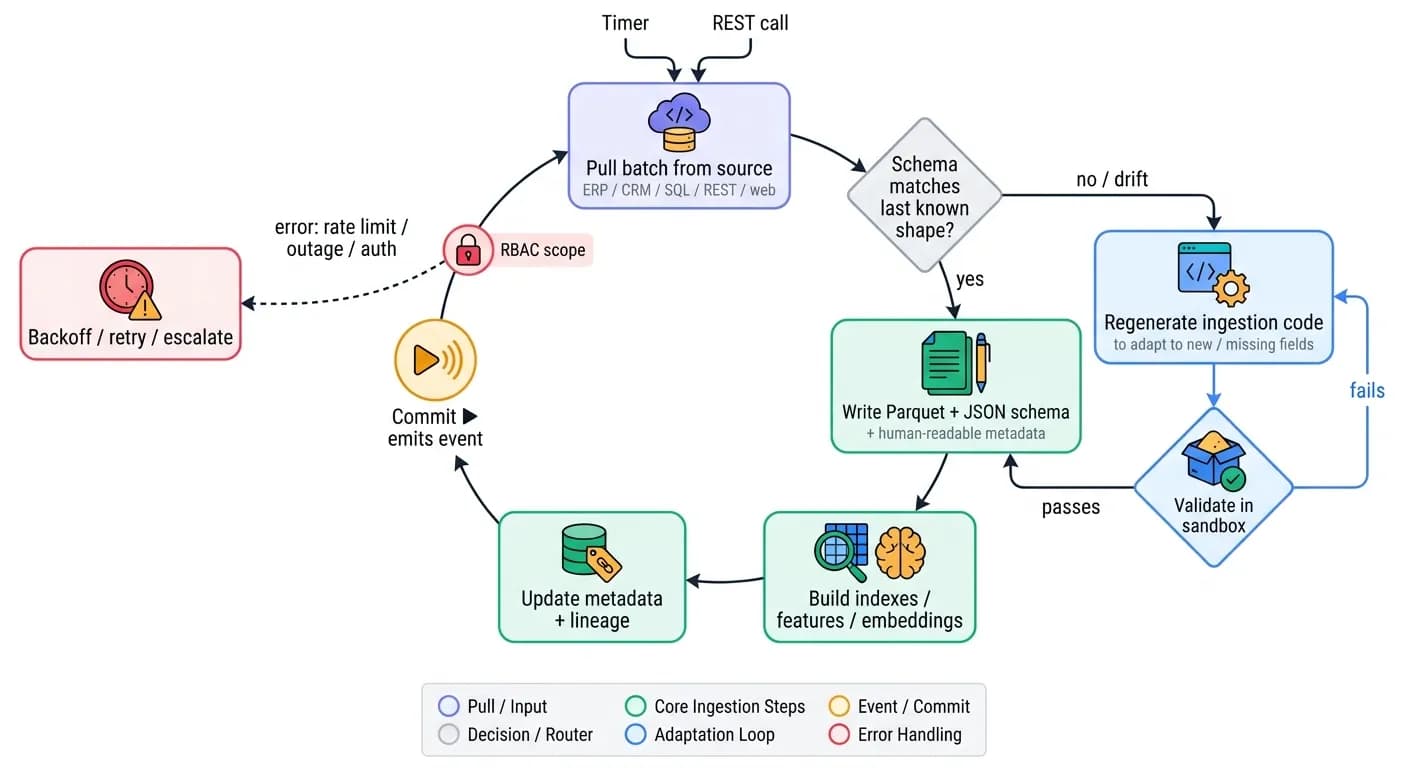
The adaptive loop is the defining feature: these agents rewrite their own code when the source changes. If the ERP adds a column, renames a field, or drops a table, the agent detects the discrepancy, regenerates the code, validates it in the sandbox, and resumes - without a human editing a connector. How agents write, validate, version, and evolve this code is detailed in Self-Coded Integrations.
| Source | Output | Adapts to |
|---|---|---|
| ERP | erp/orders.parquet + schema.json + README | new/renamed/removed fields, table splits |
| CRM | crm/accounts.parquet + schema.json + README | pipeline stage changes, custom objects |
| In-house SQL | app/transactions.parquet + schema.json + README | migrations, dropped columns |
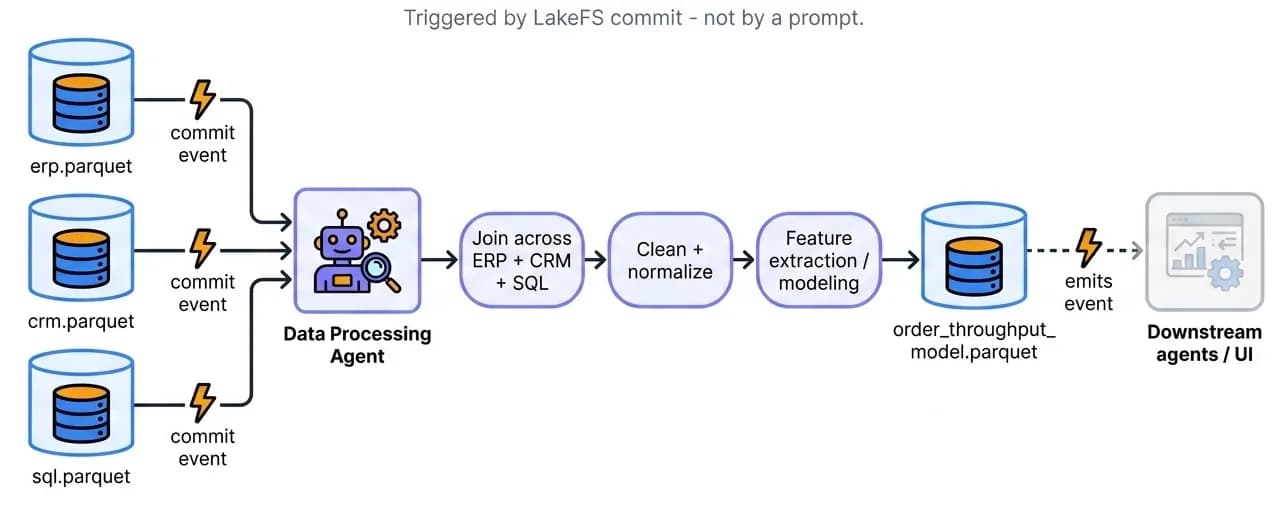
Data Processing Agents
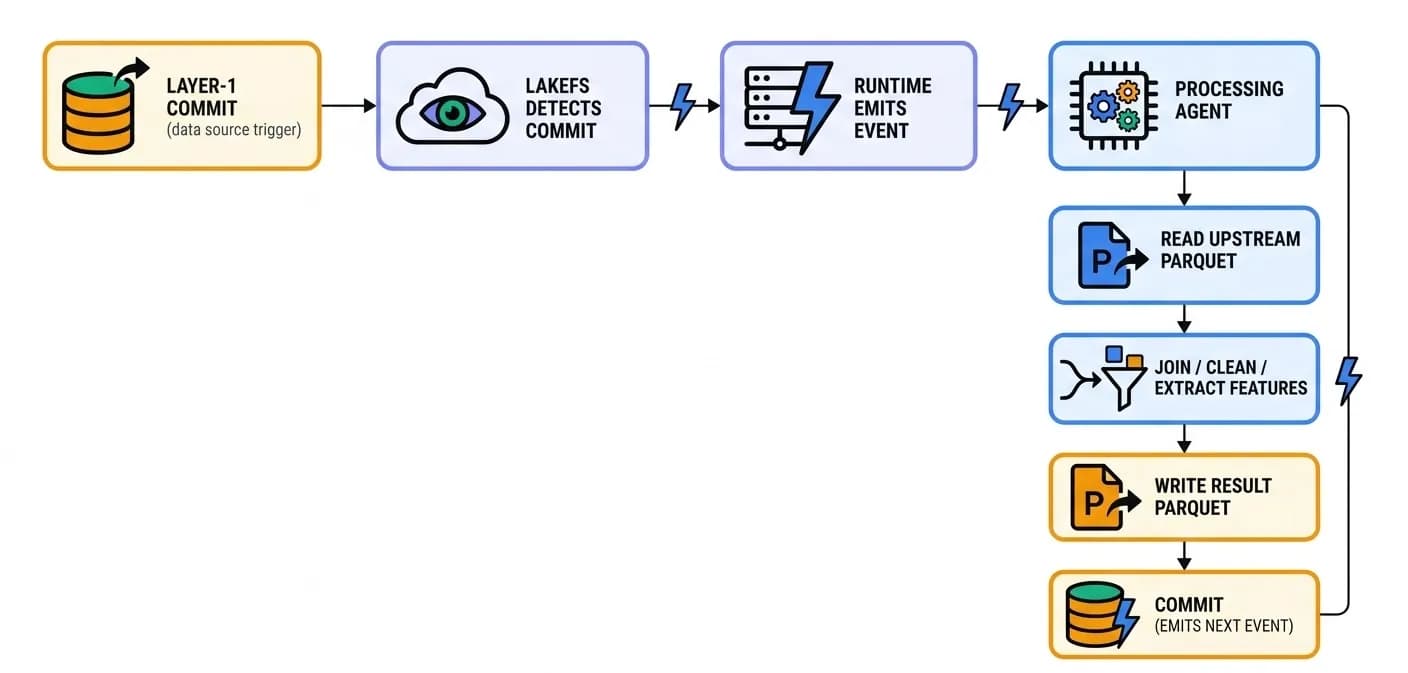
Job: turn the raw mirrors from Layer 1 into data shaped for a downstream task - joined, cleaned, and enriched. They are triggered by a change on the file system: when an ingestion agent commits new data, the runtime detects the commit on the underlying LakeFS repository and emits an event that activates the relevant processing agent. No polling, no cron - the data arriving is the trigger. Event-reactive activation across storage, workflow, external, and human triggers is covered in the Technology Deep Dive.
UI Agents
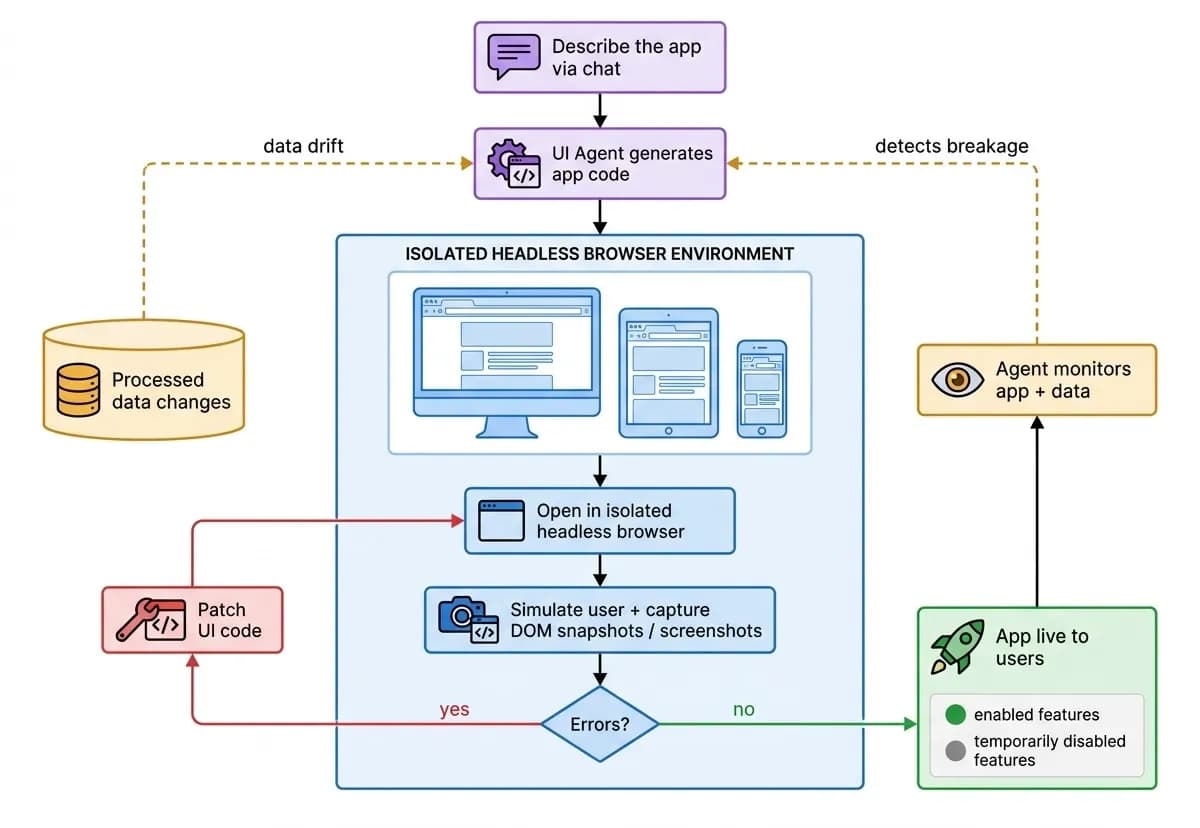
Job: generate and operate interactive web applications - reports, forms, dashboards - on top of the processed data. Users (or other agents) can “vibe-code” a UI of arbitrary complexity simply by describing it. Each app is generated and owned by an agent responsible for coding, debugging, and monitoring it, and it adapts to underlying data changes: when the data shape shifts, the owning agent detects the breakage, regenerates the affected code, and the app keeps working - see vibe-coded applications for how users build them conversationally.
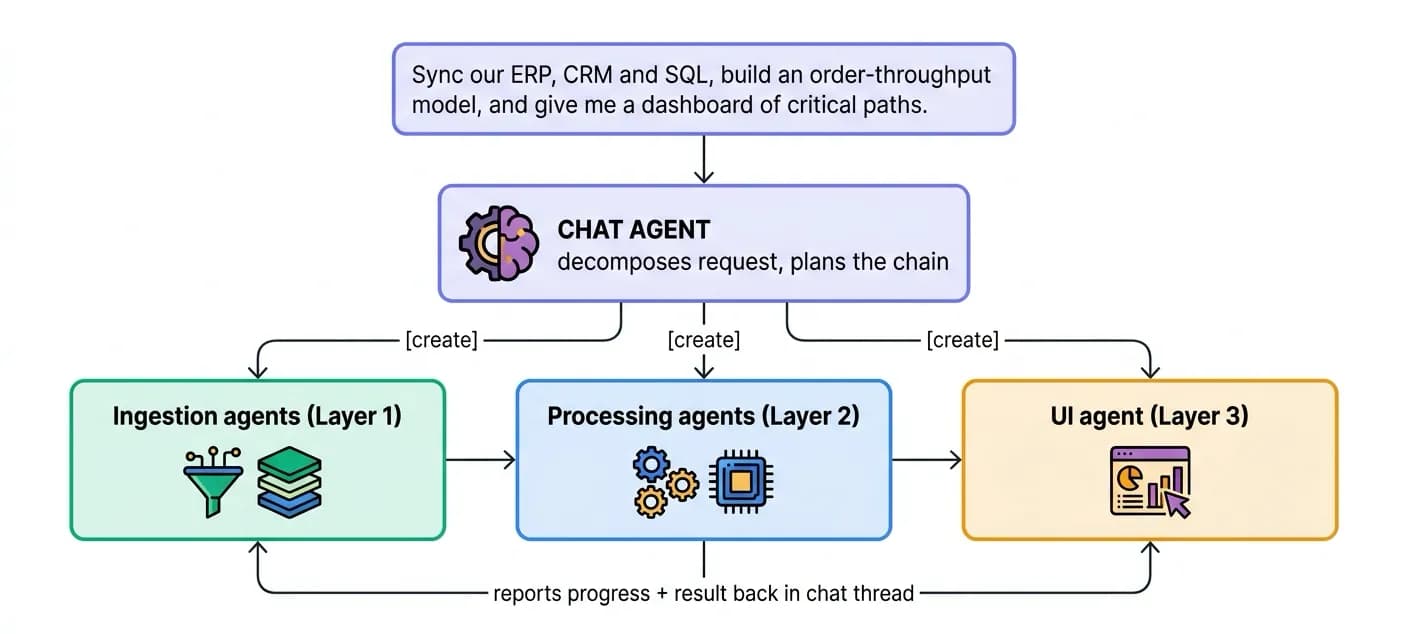
Chat Agents
Job: be the main interface to the entire system - the front door from which everything else is built, run, and queried. A single message can trigger a chain of agents spanning all three layers below. The chat agent decomposes a request, decides which agents to create or invoke, wires their handoffs, and reports back in the same thread when the (possibly long-running) work completes.
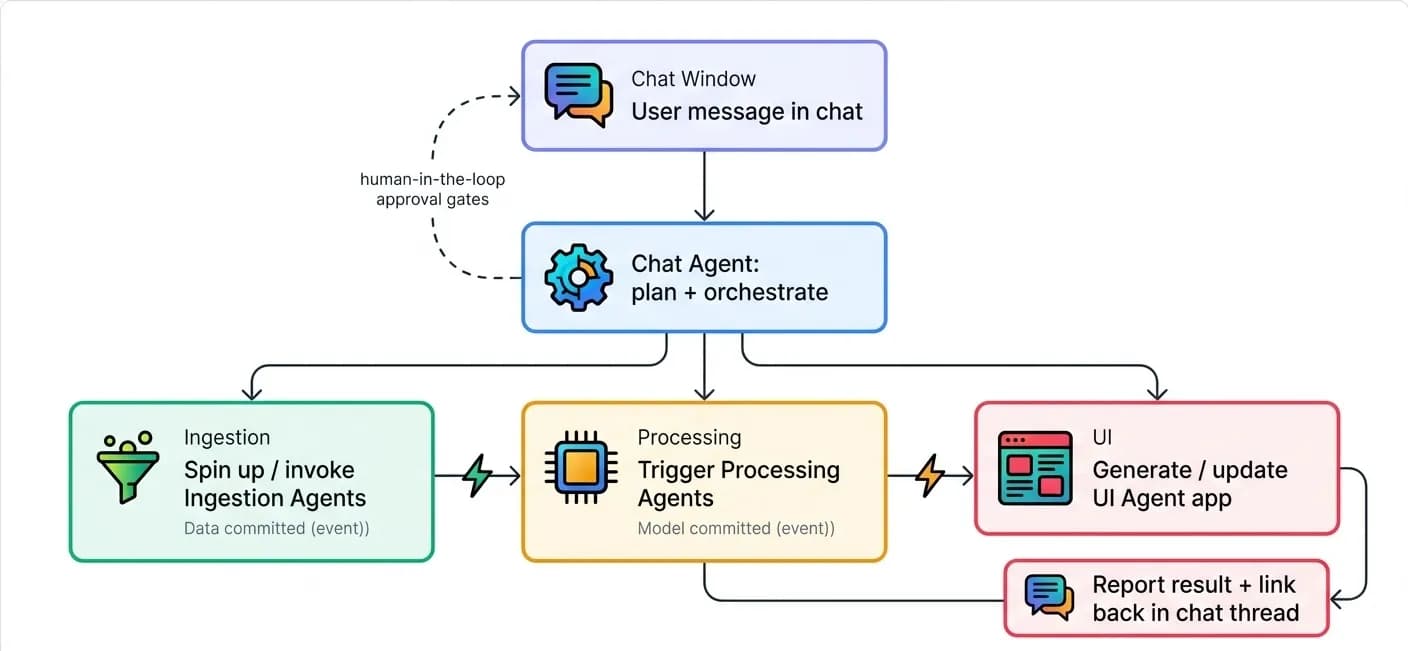
How the Layers Connect
The four agent types form a continuous, event-driven, governed pipeline.
| Layer | Agent type | Trigger | Self-healing behavior |
|---|---|---|---|
| 1 | Integration / Ingestion | Timer or REST call | Rewrites ingestion code on schema drift; backoff on rate/outage |
| 2 | Data Processing | LakeFS commit event | Re-runs on new commits; patches code on logic errors |
| 3 | UI | Build request + data-change events | Regenerates + self-debugs UI on data drift |
| 4 | Chat | Human message | Plans, retries, escalates via approval gates |
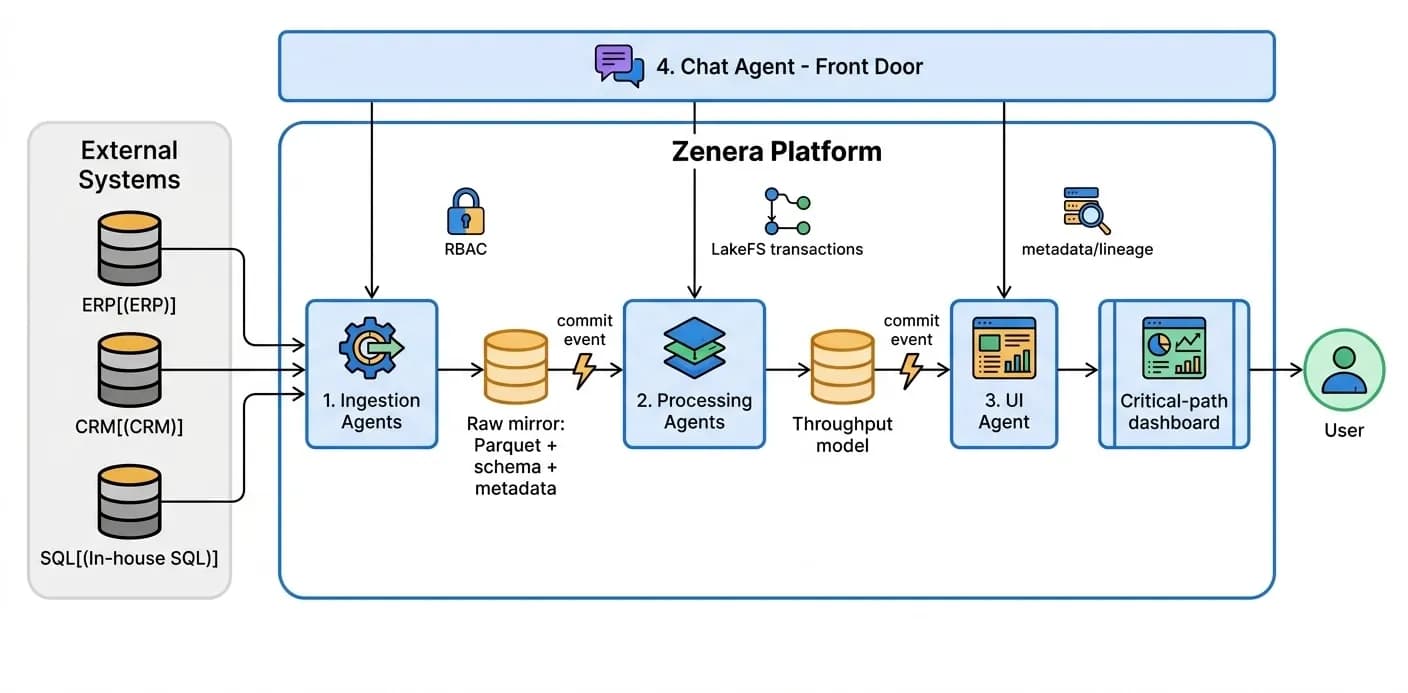
Why This Works
- Plain code, transactional storage - agents read and write a normal file system; the sandbox maps it to LakeFS branches, so every run is isolated, versioned, and crash-safe.
- Events, not polling - every commit is an event; downstream agents wake exactly when there is work to do, and the chain self-propagates from ingestion to UI.
- Self-healing at every layer - ingestion adapts to schema drift, processing patches logic errors, UI agents debug their own apps against changing data.
- Governance everywhere - RBAC scopes bound what every agent can touch; metadata and lineage make each output discoverable and auditable.
- One interface - chat is the front door; a single sentence can stand up an entire pipeline and keep it running.
"The result is an agentic system that mirrors your systems of record, reasons over them, and presents them as living applications - and keeps doing so, on its own, as those systems change underneath it."
Parallelization & Optimization
Optimizing an agentic system is nothing like optimizing traditional software - the bottleneck and the cost are the same thing: the LLM. This is the physics of that, and the two strategies Zenera leans on hardest: multi-variant planning and agentic fork/join parallelism.
Why Agentic Optimization Is Different
In a classic program, the bottleneck is CPU cycles, memory bandwidth, or disk and network I/O - and the cost of running it is effectively zero per invocation. In an agentic system the bottleneck and the cost are the same thing: the LLM. Inference is slow and expensive, and it dominates both latency and the bill.
- LLM inference is the dominant cost - in both time and money. A tool call that runs in milliseconds is free compared to the seconds (and cents) spent generating the code that made the call. The scarce resource is no longer compute - it is tokens.
- Speed and cost vary by orders of magnitude between models. A frontier reasoning model can be tens to hundreds of times more expensive and slower per token than a small fast model. The Meta-Agent routes each task to the cheapest model that can do it - but model selection alone is not enough.
- Even for a single fixed model, tokens are not one thing. Within one model there are several classes of tokens, each with a different cost and a different speed of generation or processing.
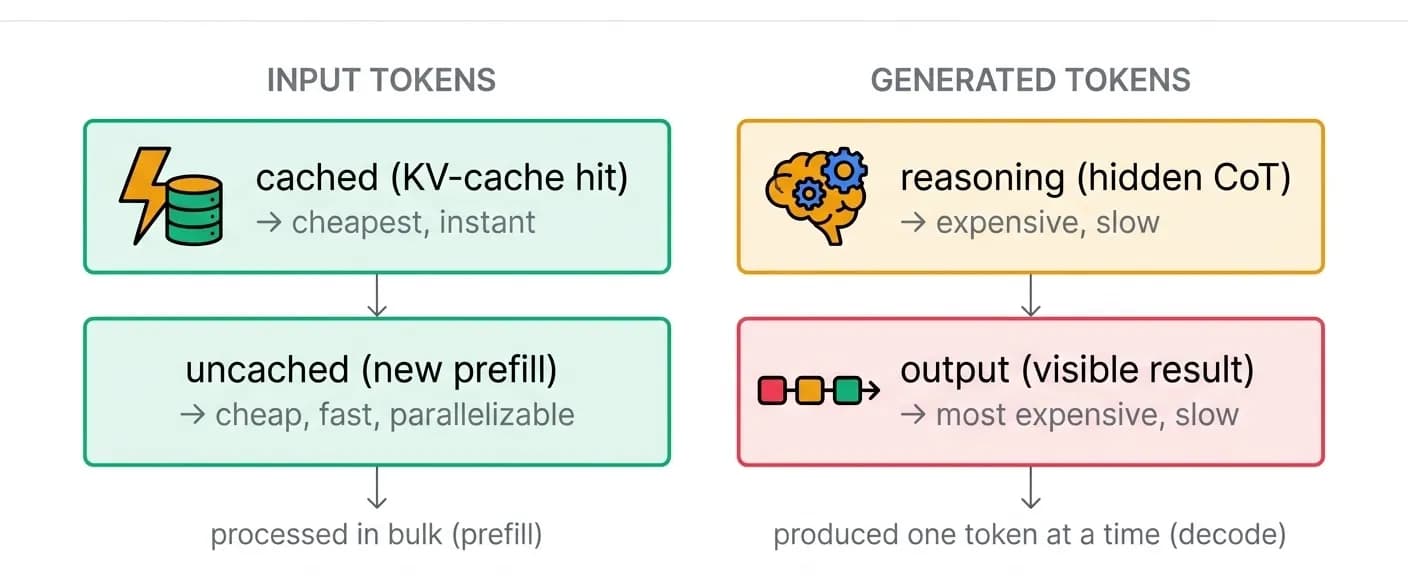
| Token class | What it is | Relative cost | Speed |
|---|---|---|---|
| Cached input (KV-cache hit) | A prompt prefix the model has already processed | Lowest | Effectively free - no recompute |
| Uncached input | New prompt tokens that must be prefilled | Low | Fast - prefill runs in parallel |
| Reasoning | Hidden chain-of-thought before the answer | High | Slow - decoded sequentially |
| Output | The visible generated result (e.g. code) | Highest | Slow - decoded sequentially |
The key asymmetry: input is cheap and parallel; generation is expensive and sequential. Reading is fast, writing is slow. Every optimization below is a consequence of that single asymmetry.
The Two Core Levers
From the token economics, two general strategies fall out - and almost every concrete optimization in Zenera is an instance of one of them.
Lever 1 - Minimize output (generated) tokens
Because generation is the slow, expensive part, the platform avoids generating tokens it does not have to.
- Patch, don't regenerate. When code needs a change, the agent emits a small diff against the existing file instead of rewriting the whole module. A 5-line patch is orders of magnitude cheaper than re-emitting a 500-line file.
- Generate a script, don't ingest the data. The agent never loads a large dataset into its context to “look at it.” Instead it writes a short script that processes the data externally in the sandbox and returns only a summary - a few hundred output tokens of code can process hundreds of gigabytes.
- Reuse prior work. Plans, skills, and previously synthesized integrations are loaded by reference rather than regenerated from scratch.
Lever 2 - Maximize KV-cache reuse
Because cached input is nearly free, the platform structures prompts so that the large, stable parts come first and never change - system instructions, loaded skills, tool definitions, the task framing. Only the small, volatile tail (the latest observation) changes between steps, keeping the expensive prefix in the KV cache across the entire agent loop.
"Together these levers reframe the goal of an agent's design: read a lot, write a little, and never re-read what you already read. Planning and fork/join are the highest-leverage expressions of that principle."
Multi-Variant Planning with Self-Assessment
The single most effective speed optimization for any token-heavy task - and code generation is the heaviest - is to plan before generating. A plan is cheap: it is short English or pseudocode. The final output is expensive. A good plan lets the agent produce correct code on the first shot, avoiding the costly cycle of generate → fail → patch → regenerate. Zenera does not ask for one plan - it asks for many, in parallel, and keeps the best.
Inference engines can emit n-best outputs from a single prompt at little extra cost (the expensive prefix is shared). Zenera launches N parallel plan streams, and within each stream asks the model to produce a sequence of M plans, each an iterative improvement of the previous one. Every plan is a structured JSON object containing:
- steps[] - the proposed plan, in English / pseudocode.
- critique_of_previous - a detailed textual assessment of the prior plan's weaknesses.
- improvements - exactly what this revision changed and why.
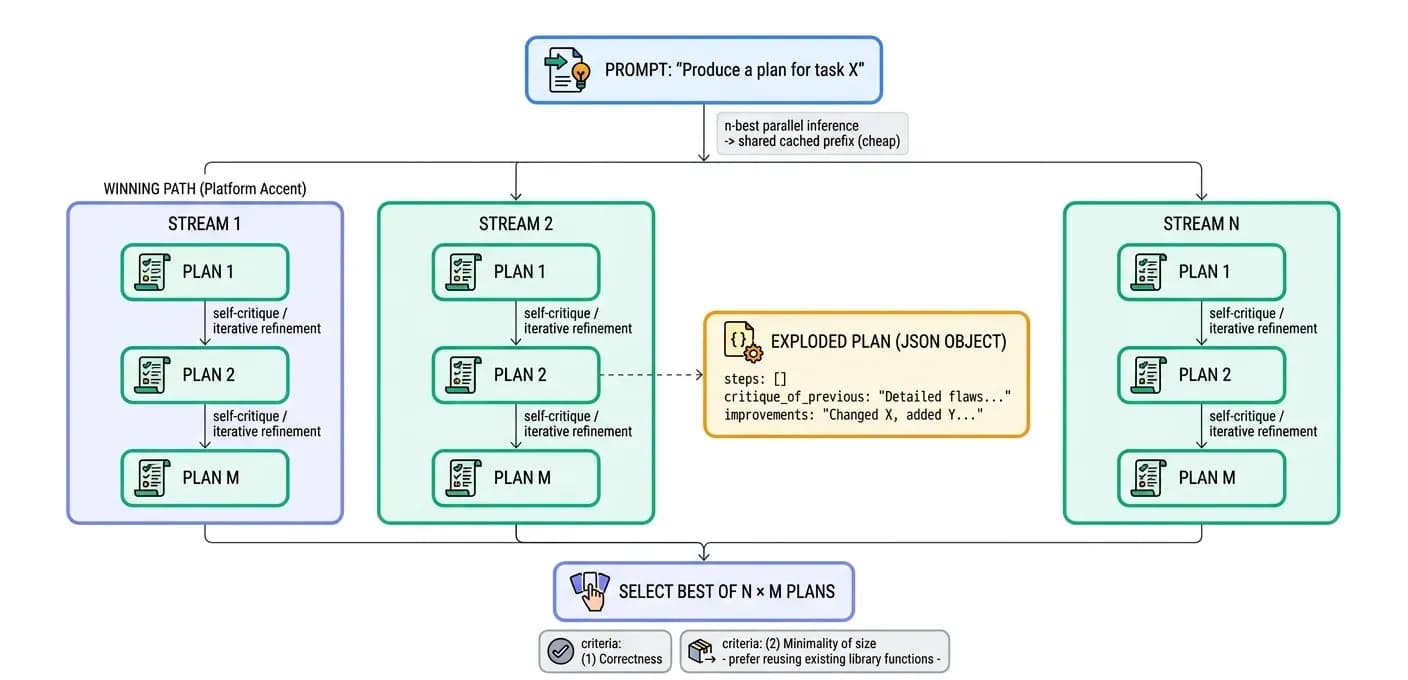
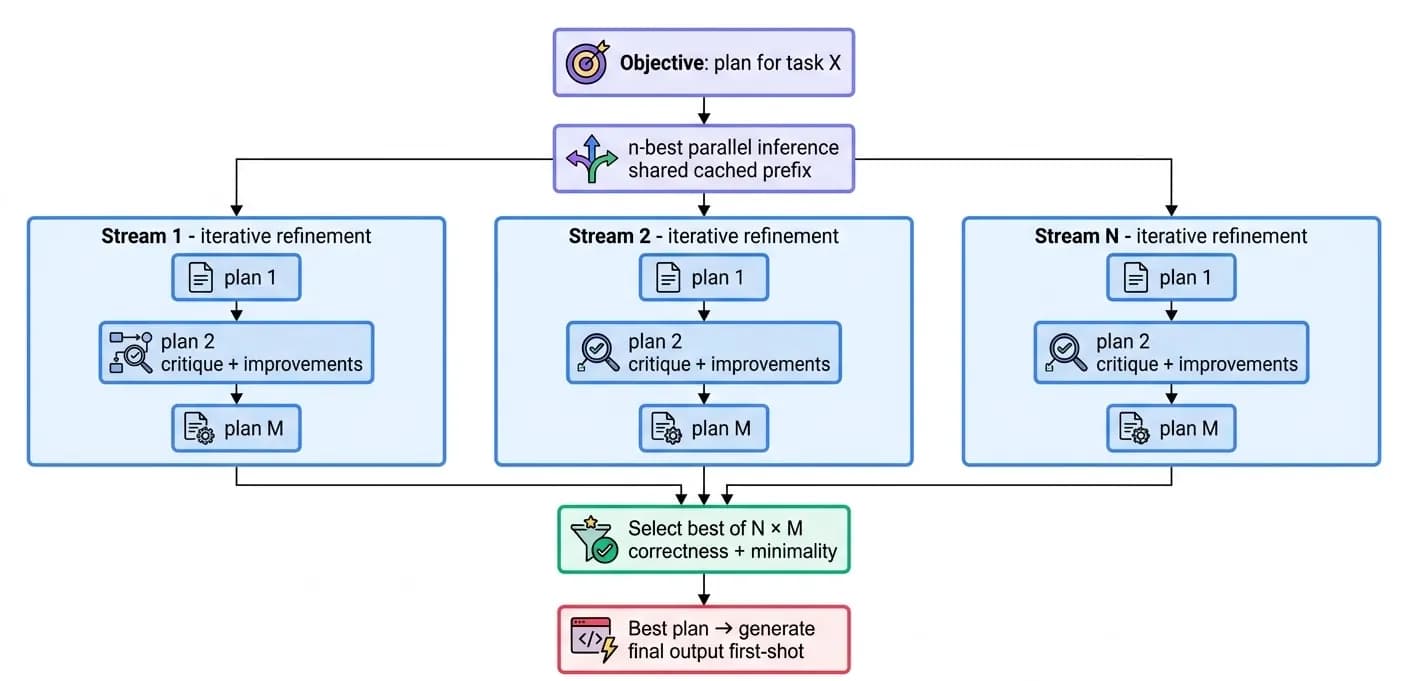
Minimality is a selection criterion. The best plan is not the most elaborate one - it is the smallest correct one. A short plan that reuses an existing library function beats a long plan that re-implements it. Ranking on correctness first, size second steers the system toward solutions that lean on what already exists. After all streams complete, Zenera holds the best of N × M plans and generates the final output once - avoiding the expensive patch-and-regenerate loop entirely.
Agentic Fork/Join Parallelism
The second cornerstone is structural: before doing a large task, stop and ask how it can be parallelized. Many agentic workloads - processing a large dataset, generating many files, integrating many sources, exploring many candidate solutions - decompose naturally into independent sub-tasks. Zenera turns that decomposition into a first-class runtime primitive: an agent can fork copies of itself, run them in parallel, and join their results.
A parent agent splits its work into K shards and forks K clones of itself. Each clone runs with the full guarantees from the Agent Runtime - its own isolated LakeFS branch (so its writes are transactional and cannot corrupt siblings), its own managed context, and its own slice of the work. The clones run concurrently; when they finish, the parent joins them, merging their committed branches into a single output.
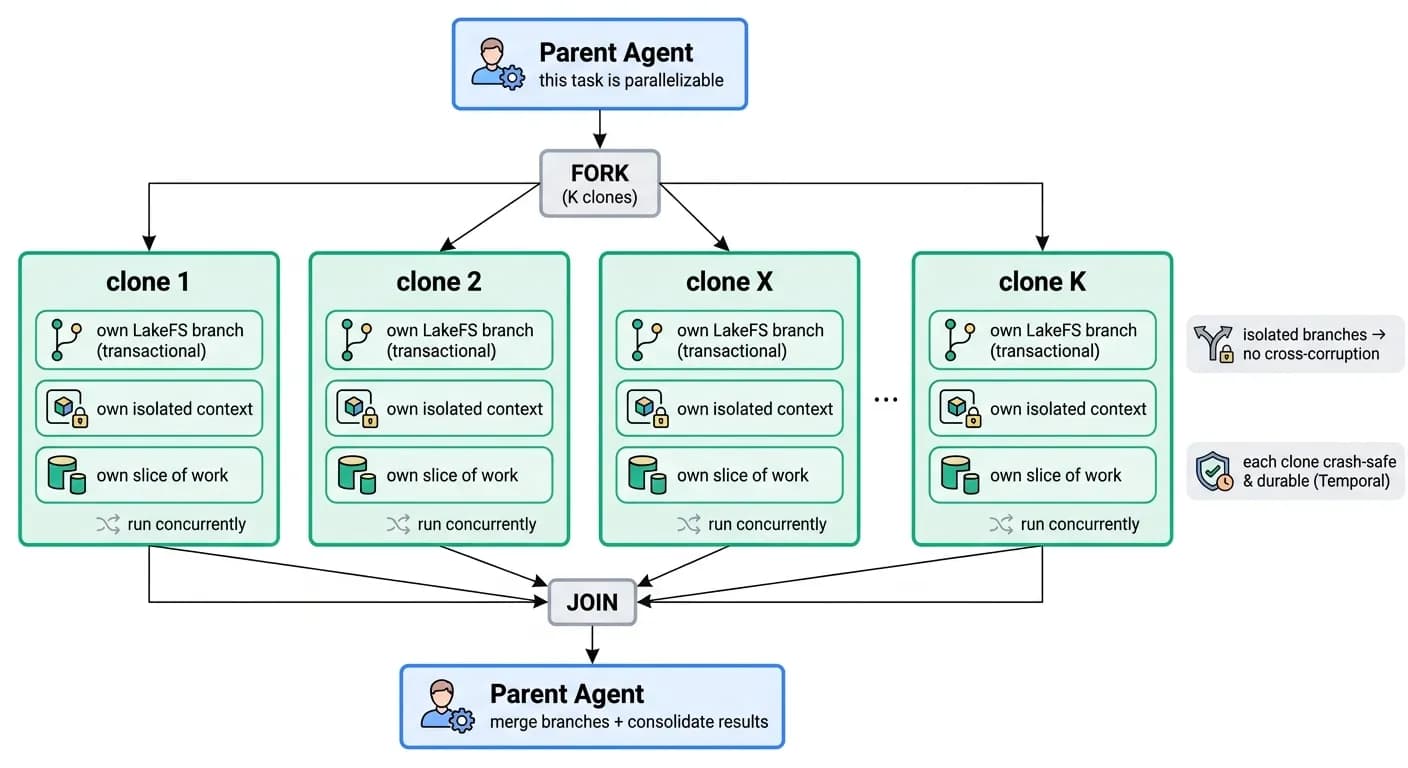
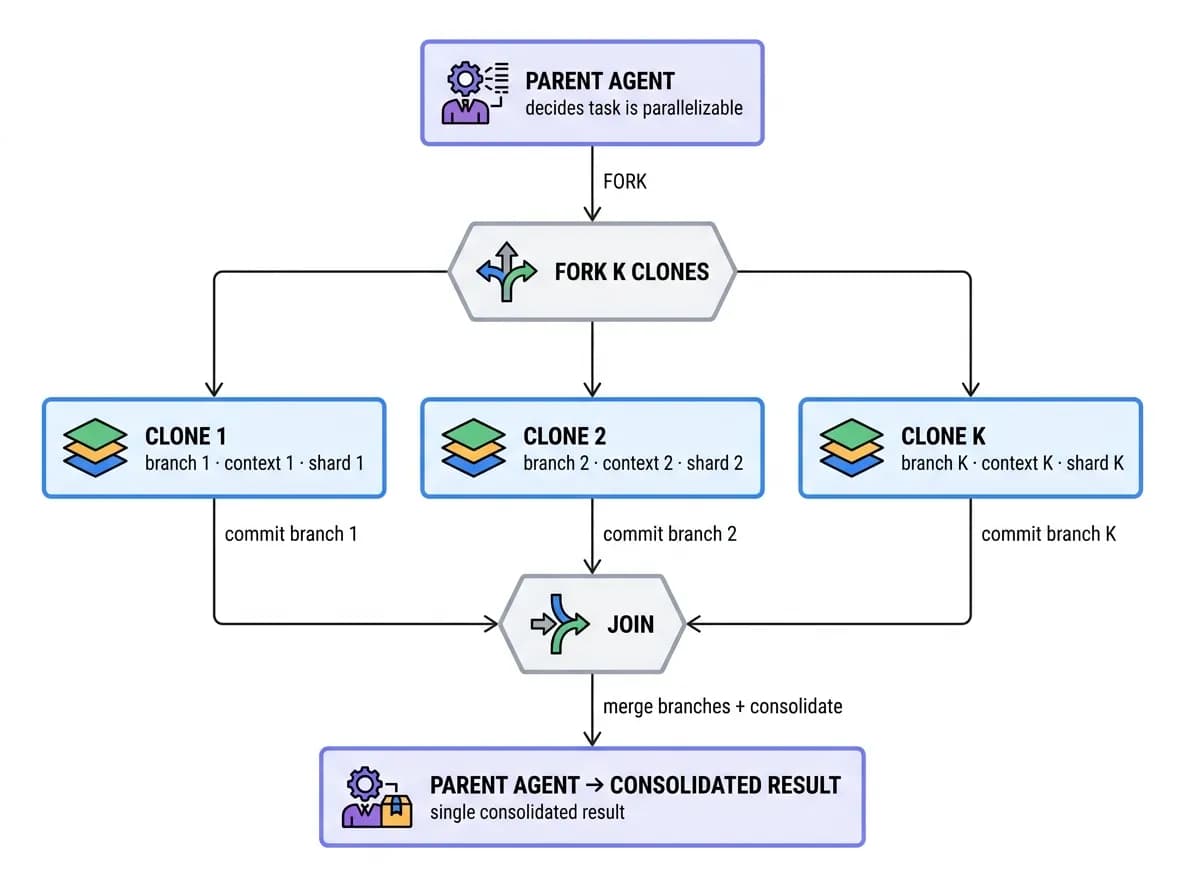
Fork/join speeds up both halves of an agent's cost. It parallelizes LLM generation - N candidate solutions or sub-plans explored at once - and it parallelizes tool and code execution - K shards of a large dataset processed simultaneously across the worker pools. Because each fork inherits the platform's transactional storage, context management, and durable-workflow guarantees automatically, parallelism here is safe by construction - no shared mutable state to corrupt, no manual locking, no bespoke checkpointing.
"Agentic fork/join is one of the cornerstones of the Zenera platform - it is what lets it execute complex workflows that combine large-scale data processing with large amounts of generated code in practical time."
Summary
Optimization in Zenera is governed by the economics of tokens, not the economics of CPU cycles.
| Strategy | Lever | What it saves |
|---|---|---|
| Model routing | Pick cheapest capable model | Orders-of-magnitude cost/latency between models |
| Patch, don't regenerate | Minimize output tokens | Re-emitting whole files |
| Script over ingest | Minimize output tokens | Streaming large data through the context window |
| Stable-prefix prompting | Maximize KV-cache reuse | Re-prefilling unchanged instructions each step |
| Multi-variant planning | Cheap planning to avoid costly regeneration | The generate → fail → patch → regenerate loop |
| Agentic fork/join | Parallelize generation and execution | Sequential grind on large, decomposable tasks |
"Reading is cheap, writing is expensive, and re-reading what you already read is waste. Zenera's optimizations all push work toward cheap, parallel, cached operations and away from expensive, sequential, repeated generation - and the fork/join runtime makes that parallelism safe to use without the agent ever thinking about isolation, transactions, or recovery."
See the Architecture in Action
From a single self-healing agent to a full agentic system that mirrors your enterprise - see how Zenera makes agents trustworthy.
Request a Demo