Transactional Execution Runtime
Sub-200ms code execution on data of any size - isolated, transactional, crash-safe, and Kubernetes-native from the ground up.
Why Code Execution Needs Its Own Runtime
Code generation and execution is the beating heart of the Zenera platform. Self-coding agents synthesize integration logic. Data pipelines transform enterprise datasets. Application generators produce full-stack code. Every one of these operations ends the same way: code runs on data, and the result must be correct, isolated, and durable.
This runtime is the execution layer of the broader Zenera architecture - see that guide for how a single agent, the runtime, and full agentic systems fit together.
Generic container orchestration is not enough. Running agent-generated code in a vanilla Kubernetes pod introduces problems that enterprise workloads cannot tolerate:
| Problem | Consequence |
|---|---|
| Cold-start latency | Spinning up a new pod takes 10-30 seconds. An agent waiting 30 seconds per tool call is useless for interactive workflows. |
| Data copying | Downloading gigabytes of enterprise data into each container wastes bandwidth, time, and storage - and creates ephemeral copies that are untracked and ungoverned. |
| No transactional safety | If a pod crashes mid-execution, partially written files corrupt the dataset. There is no rollback. No branch isolation. No recovery. |
| No execution lineage | When something goes wrong, there is no immutable record of what code ran, on what data, and what it produced. |
| Scale rigidity | Homogeneous worker pools cannot serve the heterogeneous demands of enterprise AI: some tasks need GPUs, some need air-gapped networking, some need terabytes of memory. |
"Agent-generated code is untrusted by definition. Running it without transactional isolation is the equivalent of giving every intern root access to the production database."
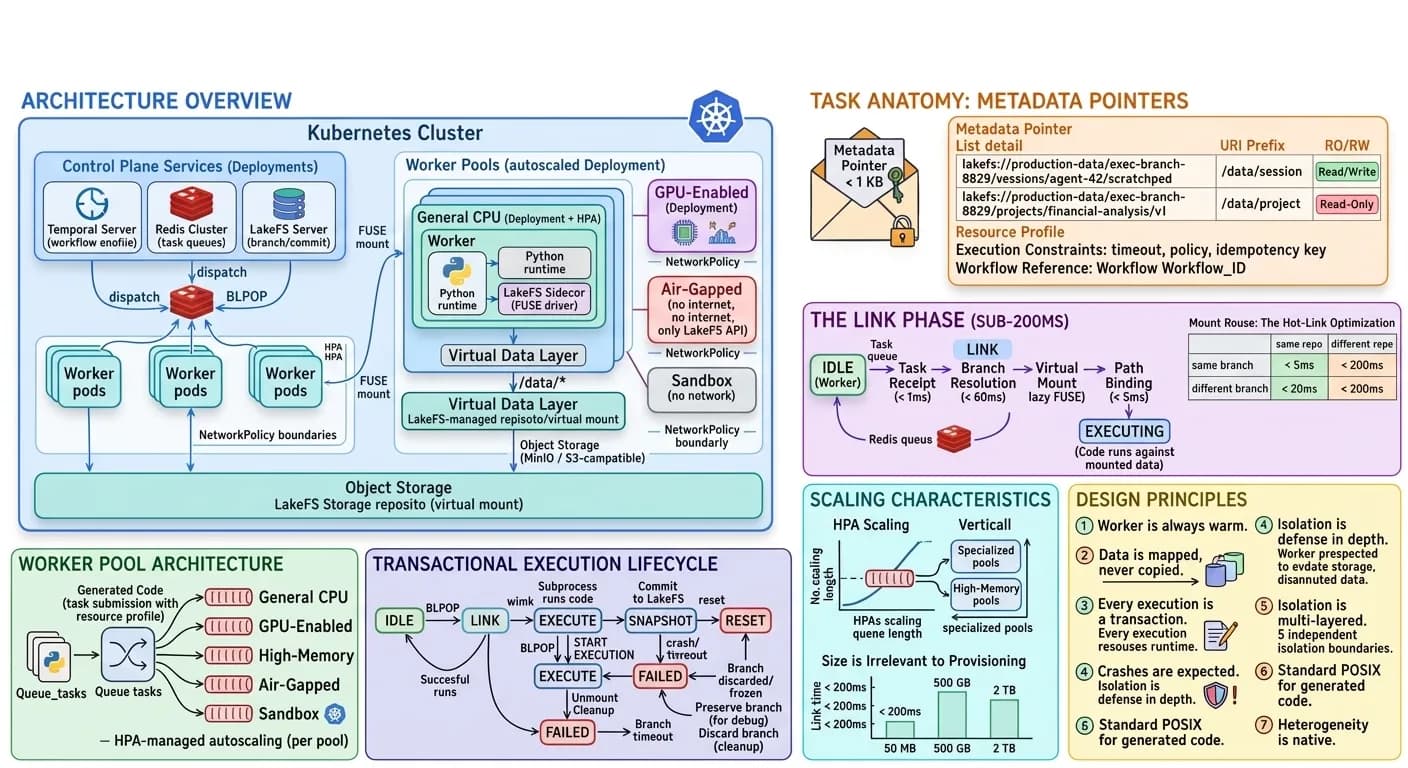
Architecture Overview
Everything runs inside the Kubernetes cluster. Temporal, Redis, LakeFS, object storage, and every worker pool are Kubernetes-native workloads. The entire runtime can be deployed in an air-gapped data center with a single Helm chart.

Three Layers
- 1Task Dispatch - Temporal workflows emit execution tasks as lightweight metadata pointers into priority-routed Redis queues.
- 2Warm Worker Pools - Pre-provisioned Kubernetes pods with runtimes already loaded, listening for work. Multiple pools with different hardware profiles (CPU, GPU, air-gapped, high-memory), each governed by its own NetworkPolicy.
- 3Virtual Data Layer - LakeFS branches mounted via FUSE sidecars inside each pod, providing instant access to datasets of any size without copying a single byte.
The Core Innovation: Data Injection, Not Data Fetching
Most execution platforms follow the same pattern: start a container, download the data, run the code, upload the results. For a 200 GB dataset, that means 200 GB of network transfer before a single line of code executes.
Zenera inverts the model entirely. Data is never copied. It is mapped.
When a task arrives, the runtime does not pull data into the worker. Instead, a high-performance FUSE driver exposes a LakeFS branch as a virtual filesystem inside the running pod. To the executing code, /data/project and /data/session appear as ordinary local directories with standard POSIX semantics.
- Files are streamed on demand - Only the bytes that the code actually reads are fetched from object storage. A 200 GB dataset where the code reads 50 MB results in 50 MB of I/O - not 200 GB.
- Writes go to the branch - Every file written by the code lands on an isolated LakeFS branch. The main dataset is untouched regardless of what the code does.
- No local storage consumed - The worker's filesystem is read-only. All mutable state lives on the versioned branch. If the pod dies, nothing is lost and nothing is corrupted.
"The code sees a local filesystem. The platform sees a versioned, transactional, streamable data layer. The two never conflict."
Task Anatomy: Metadata Pointers, Not Heavy Payloads
A task in the Zenera runtime is not a heavy object. It is a metadata pointer pushed to the Redis queue - typically under 1 KB.
Every task resolves to a set of lakefs:// URIs that define the execution context. The task envelope contains:
- Branch URI - A lakefs:// reference that identifies the repository, the execution branch, and the paths to mount. The branch is the transactional boundary.
- Resource profile - Routes the task to the appropriate worker pool (CPU, GPU, air-gapped, etc.).
- Execution constraints - Timeout, network policy, and idempotency key.
- Workflow reference - Link back to the Temporal workflow for completion callbacks and audit.
Because the task is a pointer - typically under 1 KB - queue throughput is bounded by Redis performance, not by payload size. Thousands of tasks per second is routine.
The Link Phase: From Idle to Executing in Under 200ms
The critical performance innovation - the sequence of operations between a warm worker picking up a task and the code beginning execution.
- 1Task Receipt (< 1ms) - The worker executes BLPOP on its pool's Redis queue. The moment a task arrives, the worker transitions from IDLE to LINKING.
- 2Branch Resolution (< 50ms) - The worker calls the LakeFS API to ensure the target branch exists. Branch creation is a zero-copy metadata pointer - no data is duplicated regardless of dataset size.
- 3Virtual Mount (< 100ms) - The Mounting Sidecar uses a high-performance FUSE driver to expose the LakeFS repository. This mount is lazy - zero bytes fetched until a file is actually accessed.
- 4Path Binding (< 5ms) - Task-specific branch paths are bound into the standard execution namespace. /data/session, /data/project, and /data/code appear as ordinary local directories.
- 5Execution - The worker spawns an isolated subprocess with restricted environment variables, resource cgroups, and the appropriate network policy.
Mount Reuse: The Hot-Link Optimization
In practice, most consecutive tasks on the same worker target the same LakeFS repository. The Mounting Sidecar tracks the currently mounted repository and commit, skipping what it can:
| Scenario | What Changes | What Is Reused | Overhead |
|---|---|---|---|
| Same repo, same branch | Nothing - rebind paths only | FUSE mount + branch + FUSE cache | < 5ms |
| Same repo, different branch | Branch pointer | FUSE mount + repo connection + shared ancestor cache | < 55ms |
| Different repo | Full remount | Warm pod + runtime | < 200ms |
Why This Achieves Sub-200ms (Cold) and Sub-5ms (Warm)
| Operation | Traditional | Cold Link | Warm Link |
|---|---|---|---|
| Container startup | 10-30s | 0ms (pod is warm) | 0ms |
| Data download | Minutes to hours | 0ms (lazy FUSE mount) | 0ms |
| FUSE mount | N/A | < 100ms | 0ms (already mounted) |
| Branch creation | N/A | < 50ms | 0ms (already resolved) |
| Path binding | N/A | < 5ms | < 5ms |
| Total overhead | Minutes to hours | < 200ms | < 5ms |
"The cold path guarantees sub-200ms for any task on any data. The warm path - which covers the majority of real workloads - delivers sub-5ms dispatch. For an interactive agent, the runtime is effectively invisible."
Worker Pool Architecture
Enterprise AI workloads are not uniform. Zenera operates multiple specialized worker pools, each configured for a class of workload.

| Pool | Hardware | Network | Workloads |
|---|---|---|---|
| General CPU | Multi-core CPU, 16-64 GB RAM | Standard egress rules | Data transforms, API integrations, report generation |
| GPU-Enabled | NVIDIA A100/H100, 80+ GB VRAM | Standard egress rules | Model inference, embedding generation, image/video processing |
| High-Memory | 256-1024 GB RAM | Standard egress rules | Large dataset joins, in-memory analytics, graph processing |
| Air-Gapped | General CPU | No internet access | Regulated data processing, classified workloads, PII handling |
| Sandbox | Minimal CPU, 4 GB RAM | No network at all | Untrusted agent-generated code, integration testing |
Each pool runs as a Kubernetes Deployment with a Horizontal Pod Autoscaler (HPA). When load drops, pools scale down to a configurable minimum - warm workers are always available for sub-200ms dispatch.
Transactional Execution Lifecycle
Every code execution follows a strict state machine that guarantees data consistency, crash safety, and complete auditability.

Task Arrival
IDLE → LINK
The worker listens on its pool's Redis queue via BLPOP. Upon receiving a task, it validates the idempotency key, resolves the LakeFS branch (zero-copy metadata operation), establishes the FUSE mount, and binds task-specific paths into the execution namespace.
Isolated Execution
LINK → EXECUTE
The worker spawns an isolated subprocess with restricted environment, cgroup-enforced resource limits, read-only root filesystem, and Kubernetes NetworkPolicy per pool. The code interacts with data through standard POSIX file operations - no knowledge of LakeFS or the transactional layer required.
Atomic Commit
EXECUTE → SNAPSHOT
On successful exit, the worker triggers a LakeFS commit - an atomic snapshot of all files written during execution. The commit includes task_id, workflow_id, execution duration, resource consumption, and a hash of the executed code for complete auditability.
Cleanup
SNAPSHOT → RESET
Paths are unmounted, FUSE cache is cleared, and a completion signal is sent to the originating Temporal workflow with commit reference, execution metrics, and output summary. The worker returns to IDLE.
"A pod crash mid-execution is a non-event. The main branch is untouched. The workflow retries. The data is intact. This is what transactional execution means."
Crash Safety and Recovery
In enterprise Kubernetes deployments, crashes are routine - node evictions, OOM kills, spot instance reclamation, rolling upgrades. The runtime is designed so that crashes are operationally invisible.
When a Worker Dies Mid-Execution
- Data is safe - All writes were going to an isolated LakeFS branch. No commit was issued, so the main branch is pristine. The partial branch is preserved for debugging or garbage-collected.
- Task is retried - The Temporal workflow detects the activity timeout and dispatches the task again. The idempotency_key ensures duplicate execution is idempotent.
- No orphaned state - Because the worker's filesystem is read-only and all mutable state lives on the LakeFS branch, there is nothing to clean up in the crashed pod.
- No data pollution - Temporary branches from failed executions are tracked by the runtime's garbage collector and deleted after a configurable TTL.
When the Entire Cluster Restarts
- Temporal replays - The durable workflow engine replays workflow history from persistent storage. Every in-flight task is re-dispatched.
- Workers warm up - The autoscaler provisions warm workers across all pools. Pool minimums ensure baseline capacity within seconds.
- FUSE mounts re-establish - Mounting Sidecars lazily reconnect to LakeFS. No data migration required.
- Execution resumes - Tasks picked up by warm workers. From the workflow's perspective, it experienced a brief timeout - not a catastrophic failure.
Scaling Characteristics
Purpose-built pools scale independently - horizontally, vertically, and across any data volume with the same sub-200 ms link latency.
More Workers, More Throughput
Horizontal
Each pool scales independently based on queue depth. Workers are warm (runtime loaded, FUSE driver initialized), so scale-up latency is just Kubernetes pod scheduling - 5-15 seconds for pre-pulled images.
Bigger Workers, Bigger Problems
Vertical
For workloads exceeding a single worker's capacity, specialized pool definitions provision workers with up to 1 TB of RAM or multi-GPU configurations. Pool definitions are standard Kubernetes resource specifications - declarative and version-controlled.
Size Is Irrelevant to Provisioning
Data Scale
Whether the dataset is 50 MB or 500 GB, the Link Phase takes the same < 200ms. No pre-staging. No capacity planning for data transfer. Multi-terabyte datasets are routine.
Security and Isolation Model
Every code execution passes through five independent isolation boundaries.

Five Layers of Isolation
Branch Isolation
Code operates on an isolated LakeFS branch. Reads and writes are scoped. Cannot access other branches, sessions, or agents' data. Failures are free - discard the branch and retry.
Filesystem Isolation
Root filesystem is read-only. Writable paths limited to /data/session and /tmp. No persistent state on the worker.
Process Isolation
Code runs in a subprocess with restricted environment variables and cgroup-enforced CPU, memory, and time limits.
Network Isolation
Kubernetes NetworkPolicy per pool. Sandbox: no network. Air-gapped: no internet. General: scoped egress to whitelisted endpoints.
Audit Isolation
Every execution is immutably logged: code hash, data branch, inputs, outputs, duration, resource consumption. Complete chain of custody.
Network Isolation: Defense in Depth
| Pool | Allowed Egress | Rationale |
|---|---|---|
| General | LakeFS API, internal services, scoped external APIs | Standard business integrations |
| GPU | LakeFS API, model registry, internal services | Model inference does not require internet |
| Air-Gapped | LakeFS API only | Regulated data must not leave the cluster |
| Sandbox | Nothing | Untrusted code gets zero network access |
"This is not a simulation of transactional semantics layered on top of a filesystem. This is actual branch-merge versioning built into the storage layer - the same semantics that make Git safe for collaborative code development, applied to enterprise data at any scale."
Observability and Audit
Every execution produces a structured execution record that feeds into the platform's trajectory and observability systems.
- Complete lineage - From the Temporal workflow that dispatched the task, through the code that ran, to the data that was produced. Every output file is traceable to the exact code and input data that generated it.
- Performance profiling - CPU, memory, I/O, and duration metrics enable the Meta-Agent to optimize resource profiles and detect performance regressions.
- Forensic debugging - The execution record plus the preserved LakeFS branch give developers a checkpointed, reproducible environment for exact failure reproduction.
- Compliance evidence - For regulated industries, the immutable execution record combined with the versioned data branch provides auditable proof of what code operated on what data, when, and with what result.
Integration with the Temporal Workflow Engine
The Transactional Execution Runtime is a Temporal activity provider - every code execution is a durable, retriable activity within a larger workflow.
Example: “Enrich Customer Portfolio” Workflow
| Activity | Pool | Commit |
|---|---|---|
| Fetch raw data from ERP | general pool | raw-data-v1 |
| Run enrichment pipeline | high-memory pool | enriched-v1 |
| Generate risk scores | gpu pool | scored-v1 |
| Produce compliance report | air-gapped pool | report-v1 |
| Merge to production | LakeFS merge | atomic |
- Independently retriable - If Activity 3 fails, Temporal retries it without re-running Activities 1 and 2.
- Versioned outputs - Each commit is an immutable checkpoint. If Activity 4 fails, outputs of Activities 1-3 are preserved and valid.
- Different pools per activity - CPU-heavy work goes to general pools, GPU inference to GPU pools, regulated data to air-gapped pools.
- Bounded by timeout - The task envelope's timeout_ms sets a hard wall-clock limit. Temporal's activity timeout wraps it with retry and escalation logic.
"Multi-step agent workflows - spanning hours, touching terabytes of data, crossing security boundaries - execute with the same transactional guarantees as a single database query."
Comparison: Zenera Runtime vs. Alternatives
| Dimension | Docker-in-Docker | Serverless | VM Sandboxes | Zenera |
|---|---|---|---|---|
| Provisioning latency | 10-30s | 1-5s (cold) | 30-60s | < 200ms |
| Data handling | Copy into container | Copy into function | Copy into VM | Virtual mount, zero copy |
| Max data size | Container disk limit | Function memory limit | VM disk limit | Unlimited (streaming) |
| Crash recovery | Lost state | Retry from scratch | Snapshot restore (slow) | Branch preserved, instant retry |
| Transactional isolation | None | None | None | LakeFS branch-merge |
| Execution lineage | Logs only | Logs only | Logs only | Versioned commits + records |
| GPU support | Complex | Limited | Manual config | Native pool routing |
| Network isolation | Manual iptables | Provider-dependent | Manual firewall | K8s NetworkPolicy per pool |
| Scaling | Manual | Auto (with cold starts) | Manual | Auto (warm pools) |
Design Principles
The worker is always warm
Cold starts are eliminated by pre-provisioning. The runtime never spins up a new container for a task - it dispatches to a running worker.
Data is mapped, never copied
The FUSE-based virtual mount makes dataset size irrelevant to provisioning time. A 200 GB dataset and a 200 KB dataset link in the same < 200ms.
Every execution is a transaction
Branch isolation ensures that code cannot corrupt shared data. Failures are free - discard the branch and retry.
Crashes are expected, not exceptional
The architecture assumes pods will die. Temporal retries. LakeFS preserves. The system converges to the correct state.
Isolation is defense in depth
Five independent layers - branch, filesystem, process, network, audit - ensure that no single failure in isolation can compromise the system.
Standard POSIX for generated code
Code uses open(), os.path, pandas.read_csv(). It does not need to know about LakeFS, S3, or the transactional layer.
Heterogeneity is native
Different workloads get different hardware, different network policies, and different trust levels - without changing the code running inside.
"The Transactional Execution Runtime is where Zenera's architectural promises become physical reality: self-coding agents generate code, the runtime executes it transactionally, on data of any size, with crash safety, security isolation, and sub-200ms provisioning - on Kubernetes, at enterprise scale."
Explore the Runtime
See how transactional execution, branch isolation, and warm worker pools power enterprise-grade code execution.
Request a Demo